Week 5 — Bayesian Networks & Causal Bayes Nets第5週 — ベイズネットと因果ベイズネット
Friday, May 29, 20262026年5月29日(金)
Step 1: introduce θステップ1:θを導入
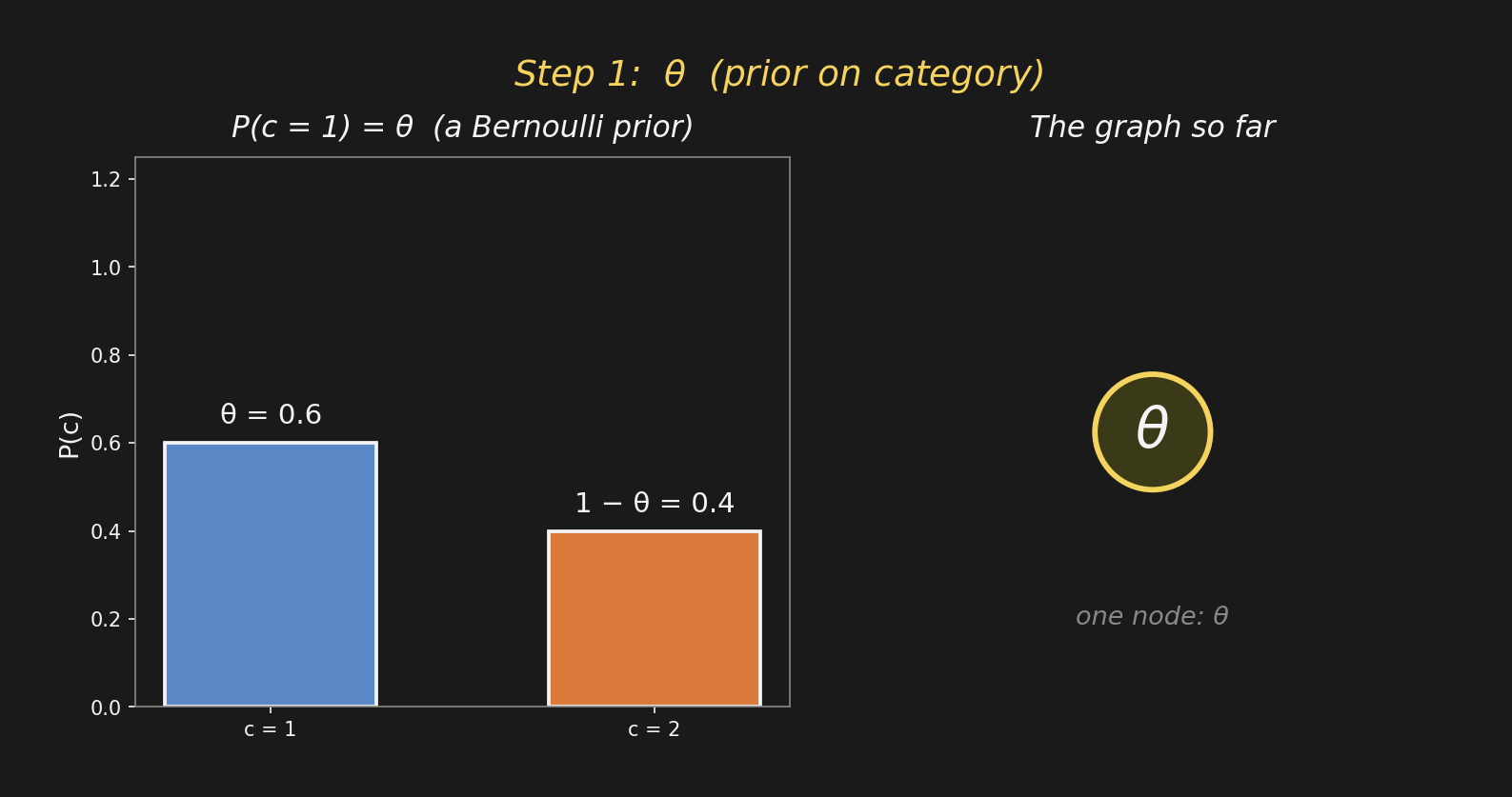
The Bernoulli prior on the left has one parameter, \(\theta\). On the right, \(\theta\) becomes one node of the graph. A node = a random variable (or parameter) in the model.
左のベルヌーイ事前分布にはパラメータ \(\theta\) が1つ。右では、\(\theta\) がグラフの ノード の1つになる。ノード = モデル中の確率変数(またはパラメータ)。
Step 2: sample \(c_n \sim \mathrm{Bernoulli}(\theta)\)ステップ2:\(c_n \sim \mathrm{Bernoulli}(\theta)\) をサンプル
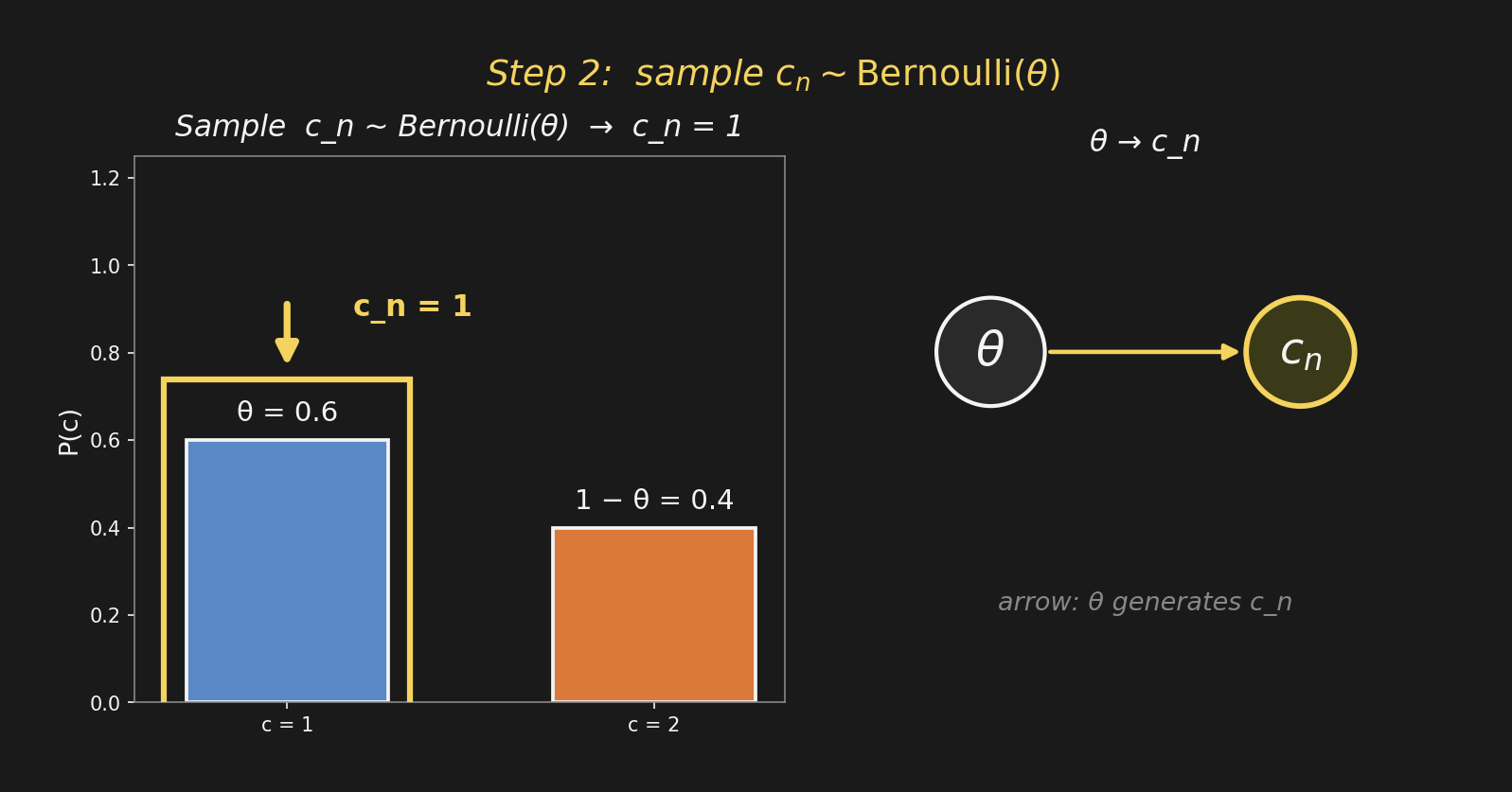
Sampling \(c_n\) flips a θ-weighted coin. Pick category 1 (highlighted bar). On the graph: \(c_n\) becomes a new node, and the line \(c_n \mid \theta \sim \mathrm{Bernoulli}(\theta)\) becomes an arrow from θ to \(c_n\).
Generative-process line ↔︎ arrow in the graph.
\(c_n\) のサンプリングは、θ で重み付けされたコインを振る。カテゴリ1 を選ぶ(黄色いバー)。 グラフの上では: \(c_n\) が新しいノードになり、\(c_n \mid \theta \sim \mathrm{Bernoulli}(\theta)\) という行は θ から \(c_n\) への 矢印 になる。
生成過程の1行 ↔︎ グラフの矢印1本。
Step 3: introduce the componentsステップ3:成分を導入
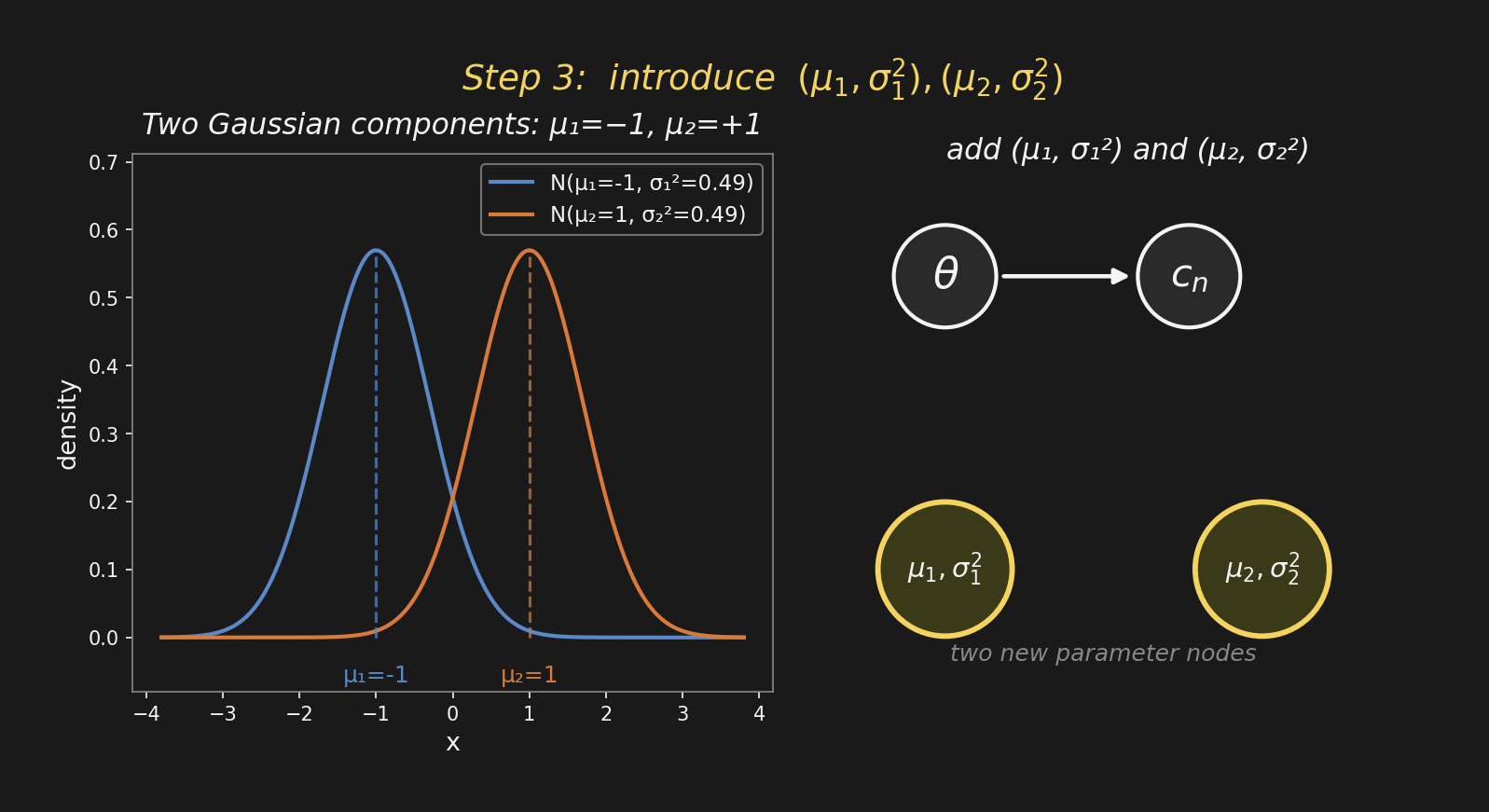
The two Gaussians have parameters \((\mu_1, \sigma_1^2)\) and \((\mu_2, \sigma_2^2)\). On the graph: two new nodes for the parameters — one pair per component.
We’re not yet drawing arrows from these into \(x_n\). That happens in the next step.
2つのガウス分布のパラメータは \((\mu_1, \sigma_1^2)\) と \((\mu_2, \sigma_2^2)\)。グラフの上では: パラメータごとに新しいノード — 成分ごとに1ペア。
まだ \(x_n\) への矢印は描かない。それは次のステップ。
Step 4: sample \(x_n\), the observationステップ4:観測 \(x_n\) をサンプル
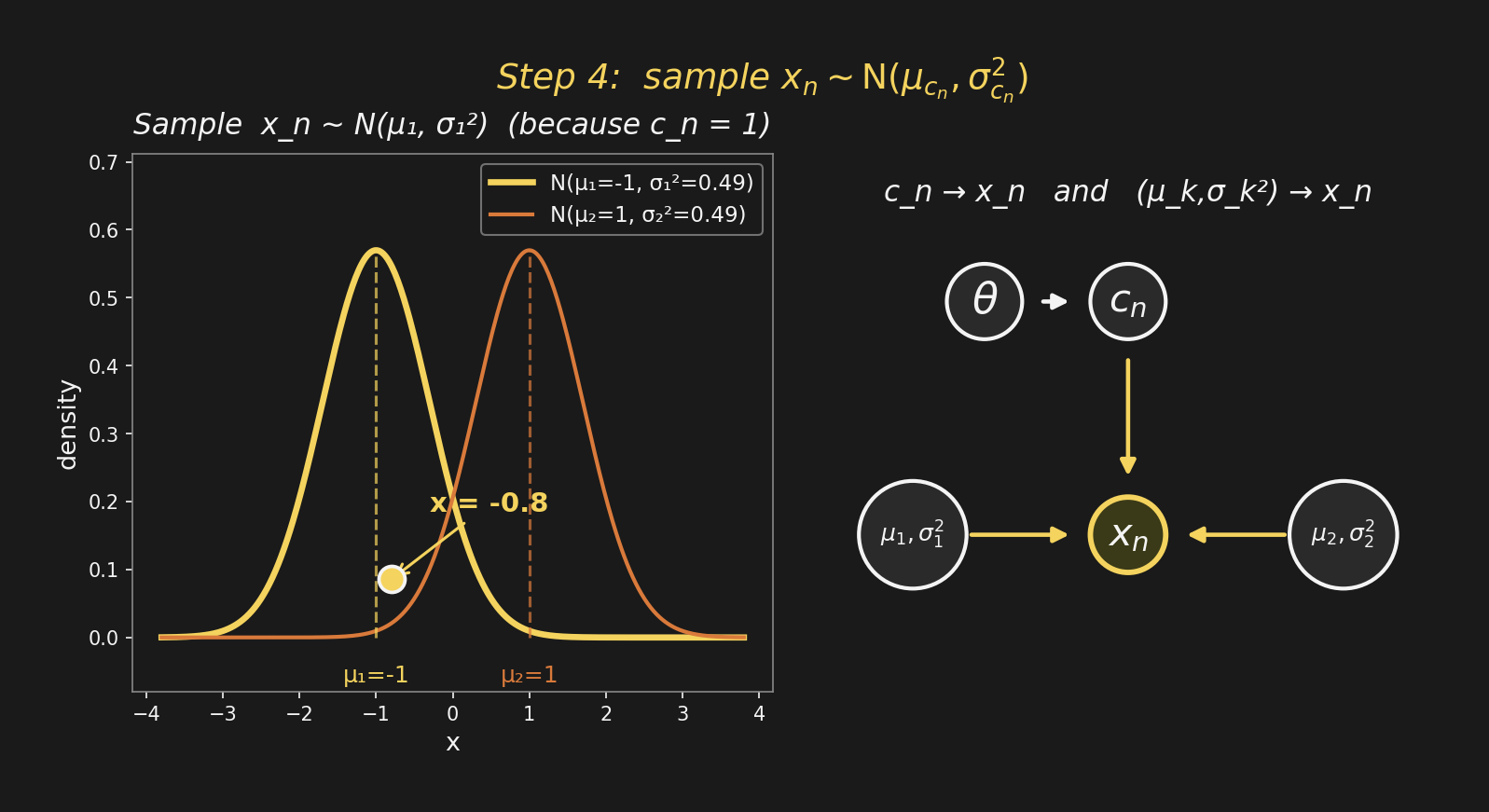
With \(c_n = 1\), we sample \(x_n \sim \mathrm{N}(\mu_1, \sigma_1^2)\) — a point under the highlighted Gaussian. On the graph: \(x_n\) is a new node (shaded — it’s observed), with arrows from \(c_n\) and from each \((\mu_k, \sigma_k^2)\).
The second generative-process line gave us three new arrows at once.
\(c_n = 1\) のとき、\(x_n \sim \mathrm{N}(\mu_1, \sigma_1^2)\) をサンプル — 黄色いガウス分布の下の1点。グラフの上では: \(x_n\) は新しいノード(網掛け = 観測済み)、\(c_n\) と各 \((\mu_k, \sigma_k^2)\) から矢印が入る。
生成過程の2行目で、矢印が3本 一気に加わった。
Step 5: do this N timesステップ5:これを N 回繰り返す
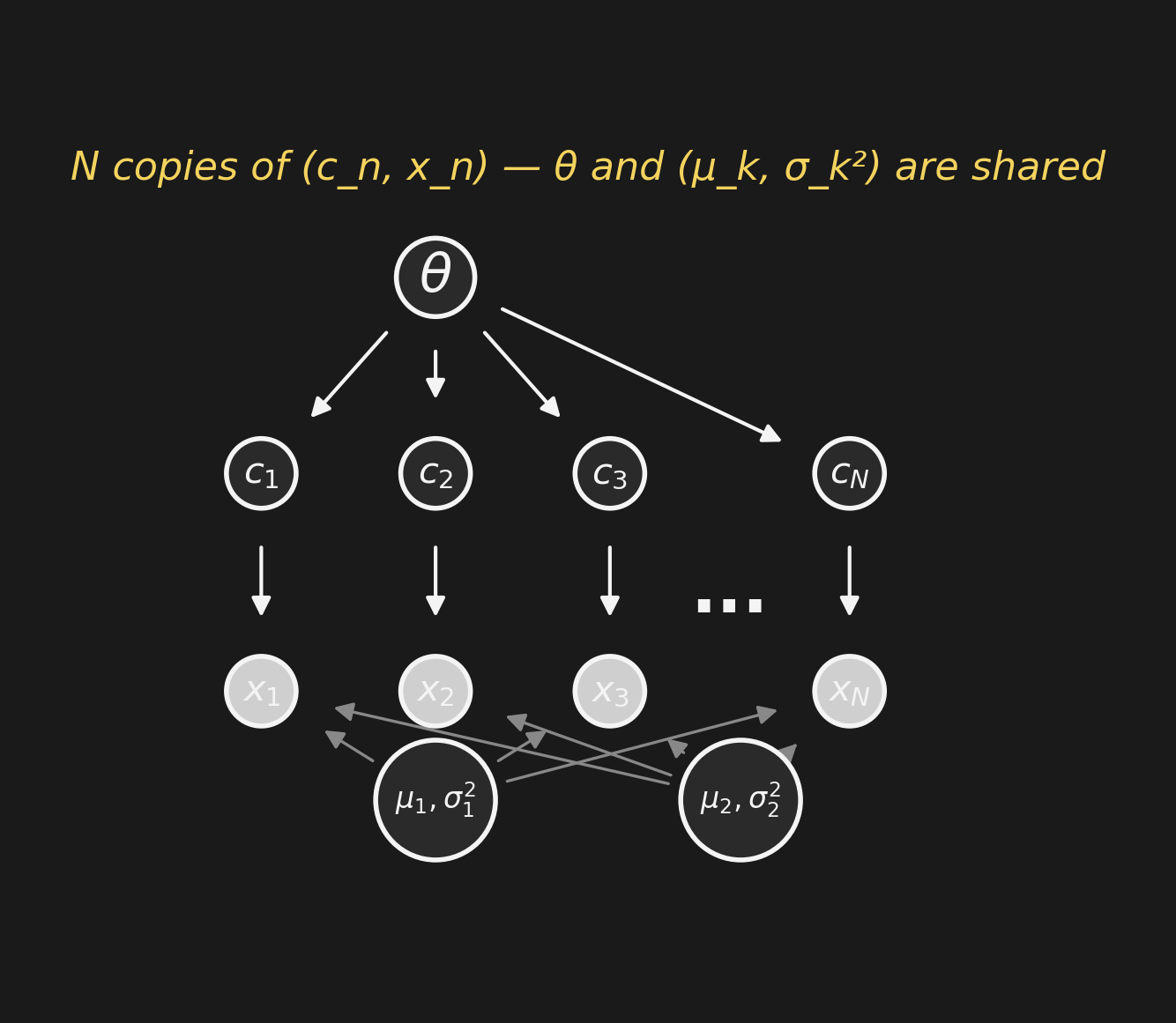
The generative process has \(n = 1, \ldots, N\). Each \(n\) gets its own \((c_n, x_n)\) — but \(\theta\) and the \((\mu_k, \sigma_k^2)\) are shared.
Drawn explicitly, this is an N-fold copy of the same little pattern.
生成過程は \(n = 1, \ldots, N\) にわたる。各 \(n\) に独自の \((c_n, x_n)\) — しかし \(\theta\) と \((\mu_k, \sigma_k^2)\) は 共有される。
明示的に描くと、同じ小さなパターンの N 個のコピー。
Step 6: the plate — a shortcutステップ6:プレート — 略記法
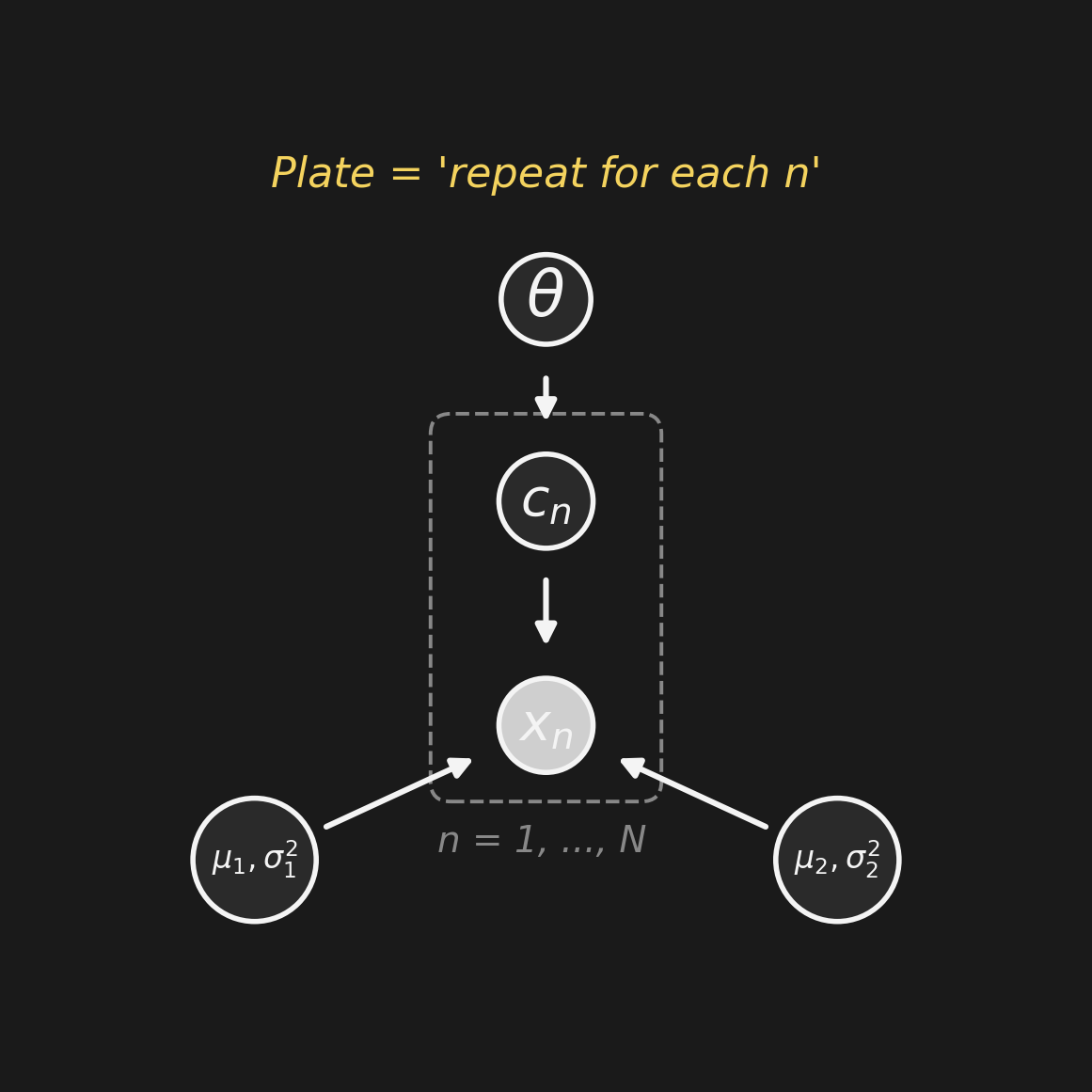
Plate notation: draw the repeating pattern once inside a dashed box, and label the box “\(n = 1, \ldots, N\).” The plate means “copy everything inside, N times.”
Same graph, vastly more compact.
プレート記法: 繰り返しパターンを 1回だけ 破線の箱の中に描き、箱に “\(n = 1, \ldots, N\)” とラベルを付ける。プレートの意味は 「中身を N 回コピー」。
同じグラフ、はるかにコンパクト。
Step 7: generalize to K componentsステップ7:K成分に一般化
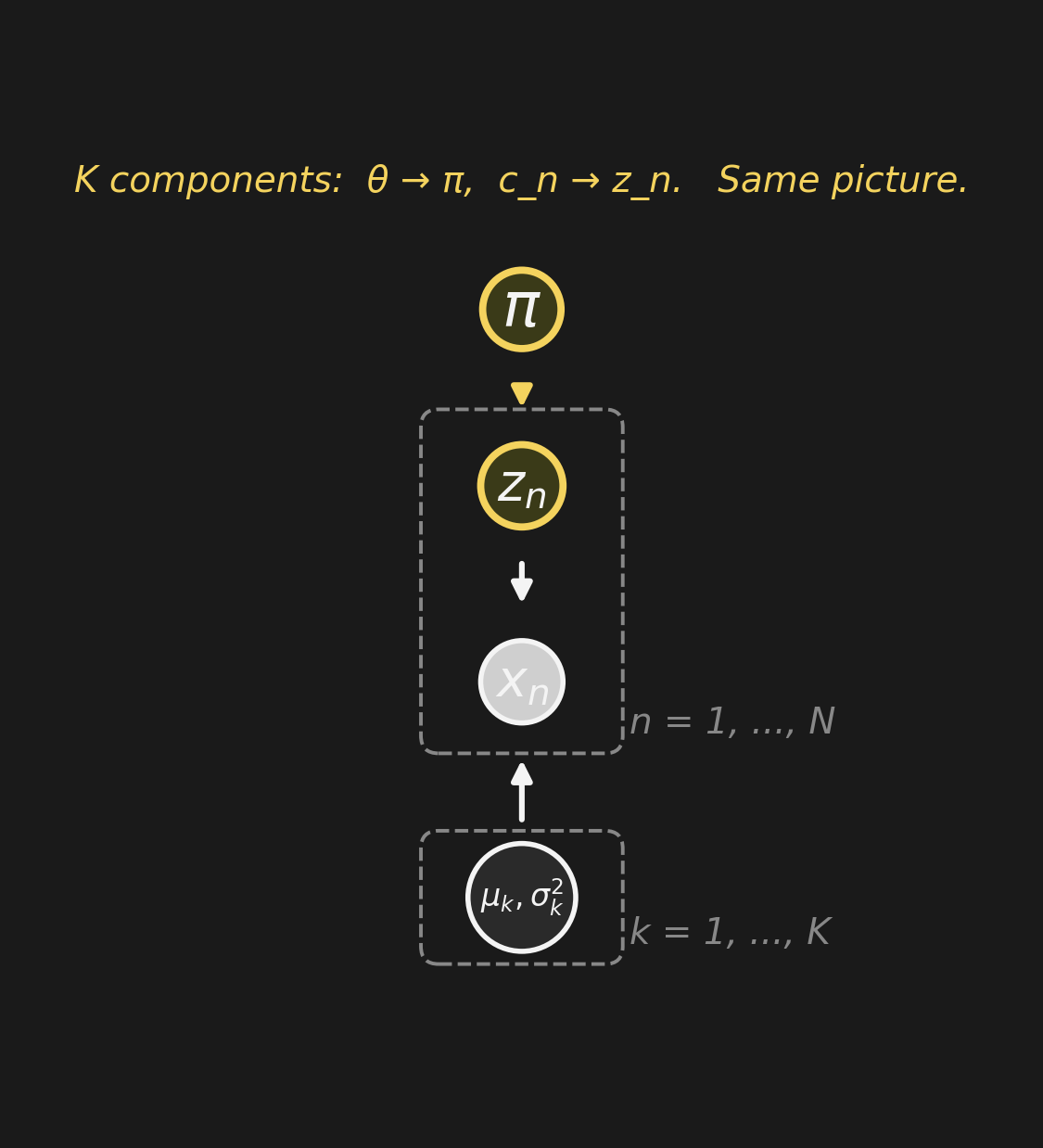
Bernoulli(\(\theta\)) generalizes to Categorical(\(\pi\)) for K components. \(c_n \to z_n\), \(\theta \to \pi\), and \((\mu_k, \sigma_k^2)\) gets a K-plate.
Same picture. Two clusters or two hundred — the graph language stayed put.
Bernoulli(\(\theta\)) は K 成分の場合の Categorical(\(\pi\)) に一般化される。 \(c_n \to z_n\)、\(\theta \to \pi\)、\((\mu_k, \sigma_k^2)\) には K-プレートを付ける。
同じ絵。 2つのクラスタでも200個でも — グラフ言語はそのまま。
The choice of K — DPMM (T3 Ch 6) avoids fixing it. Week 10 picks this up.
Where do the priors come from?事前分布はどこから来るのか?
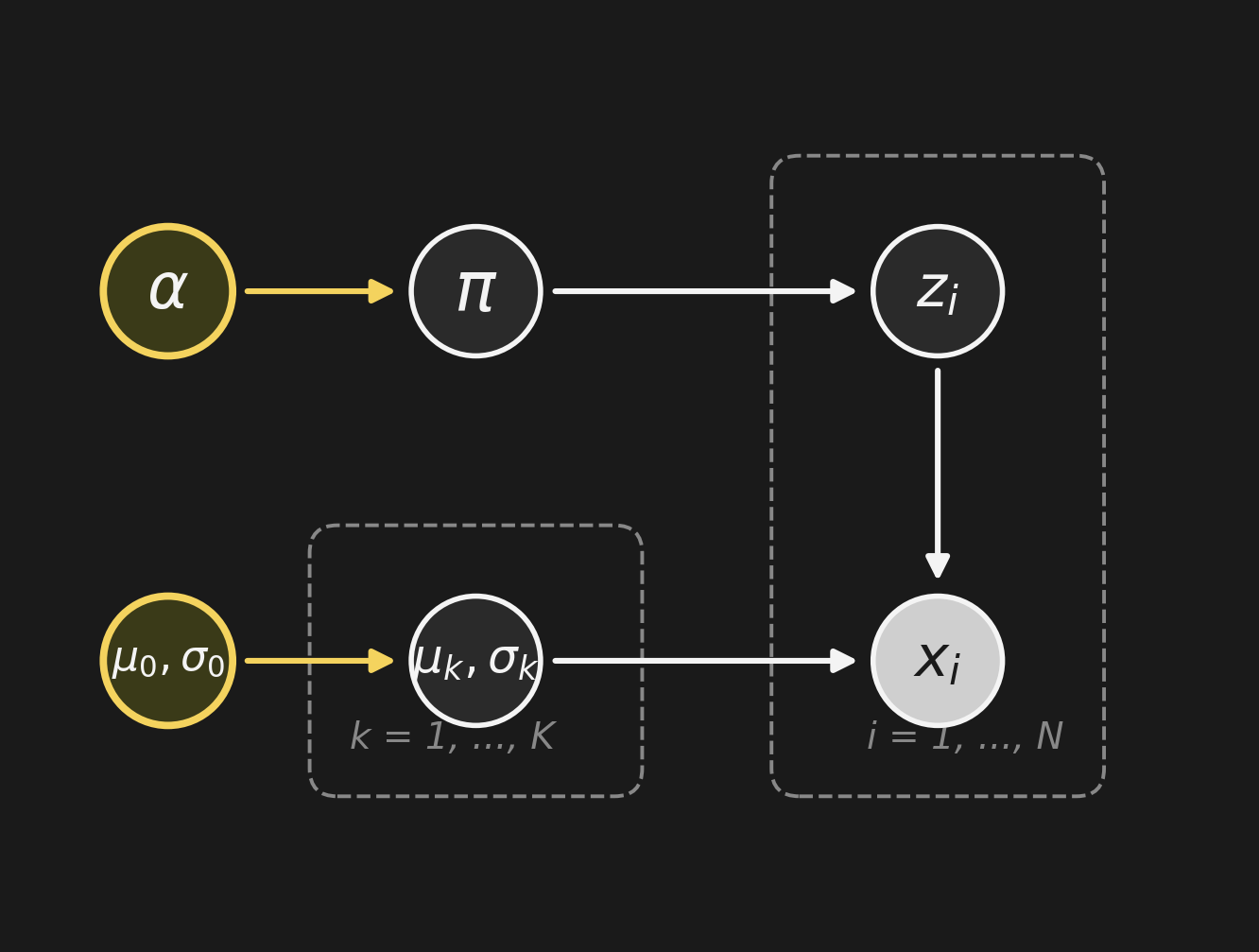
Add a hyperprior: \(\alpha \to \pi\) and \((\mu_0, \sigma_0) \to (\mu_k, \sigma_k)\).
This is exactly Week 4’s hierarchical Bayes, drawn as a graph. The graph language already covered it; we just didn’t have the words yet.
ハイパー事前分布 を追加する:\(\alpha \to \pi\) と \((\mu_0, \sigma_0) \to (\mu_k, \sigma_k)\)。
これは 先週の階層ベイズそのもの を、グラフで描いたものです。 グラフという言語ですでに表現できていたのに、その言葉を持っていなかっただけ。
Chibany’s full bento networkチバニーの完全な弁当ネットワーク
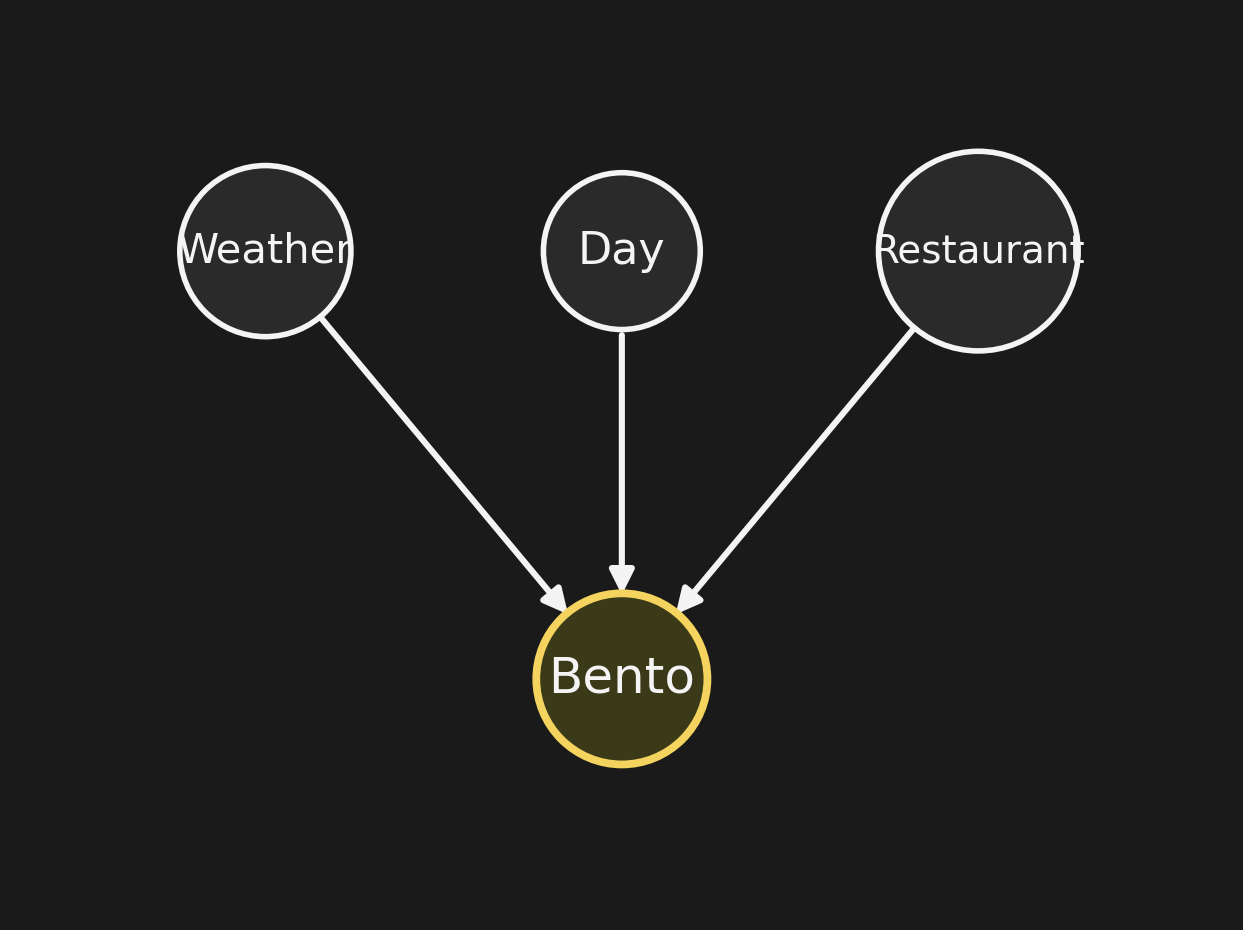
Three parents pointing into Bento. What’s the joint distribution?
3つの親ノードが弁当に向かう。同時分布は何になるか?
As a Bayes netベイズネットとして
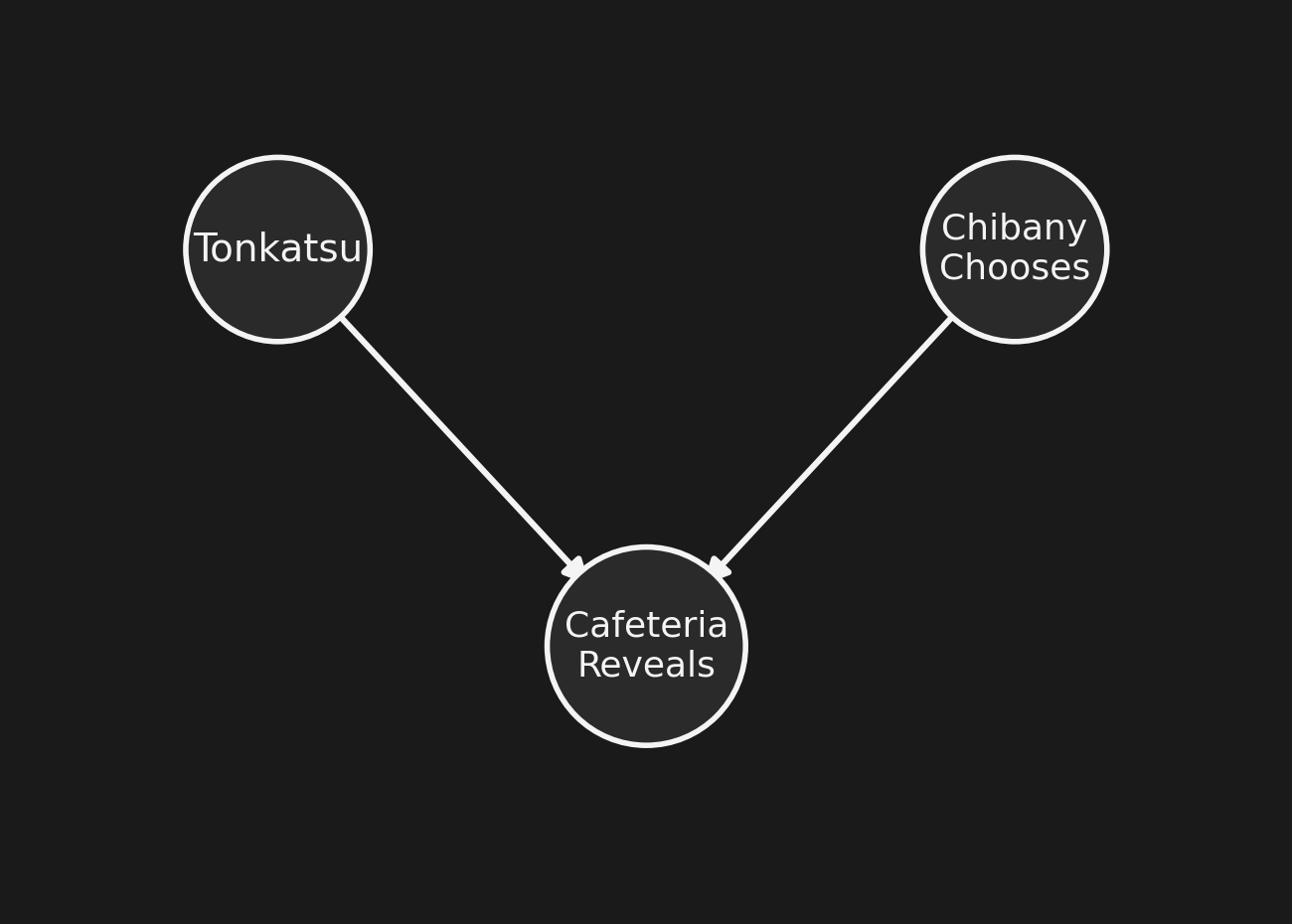
Three nodes:
- Tonkatsu (\(T\)): which box has it. Uniform: each box, 1/3.
- Chibany Chooses (\(C\)): which box Chibany chose. Independent of Tonkatsu.
- Cafeteria Reveals (\(R\)): which box the worker opens — depends on both parents.
A collider: two arrows pointing into the same node.
We’ll use \(T\), \(C\), \(R\) as shorthand for these from here on. (\(C\) for Chibany’s choice — avoids clashing with \(P(\cdot)\) for probability.)
3つのノード:
- トンカツ (\(T\)):どの箱に入っているか。一様分布:各箱 1/3。
- チバニーの選択 (\(C\)):チバニーがどの箱を選ぶか。トンカツの位置とは独立。
- 店員の公開 (\(R\)):店員がどの箱を開けるか — 両方 の親ノードに依存。
コライダー(合流点):2つの矢印が同じノードに向かう構造。
以降、これらの変数を \(T\), \(C\), \(R\) と略記します。(\(C\) は Chibany’s choice — 確率の \(P(\cdot)\) と紛れないように。)
How compact is this?どれくらいコンパクトか?
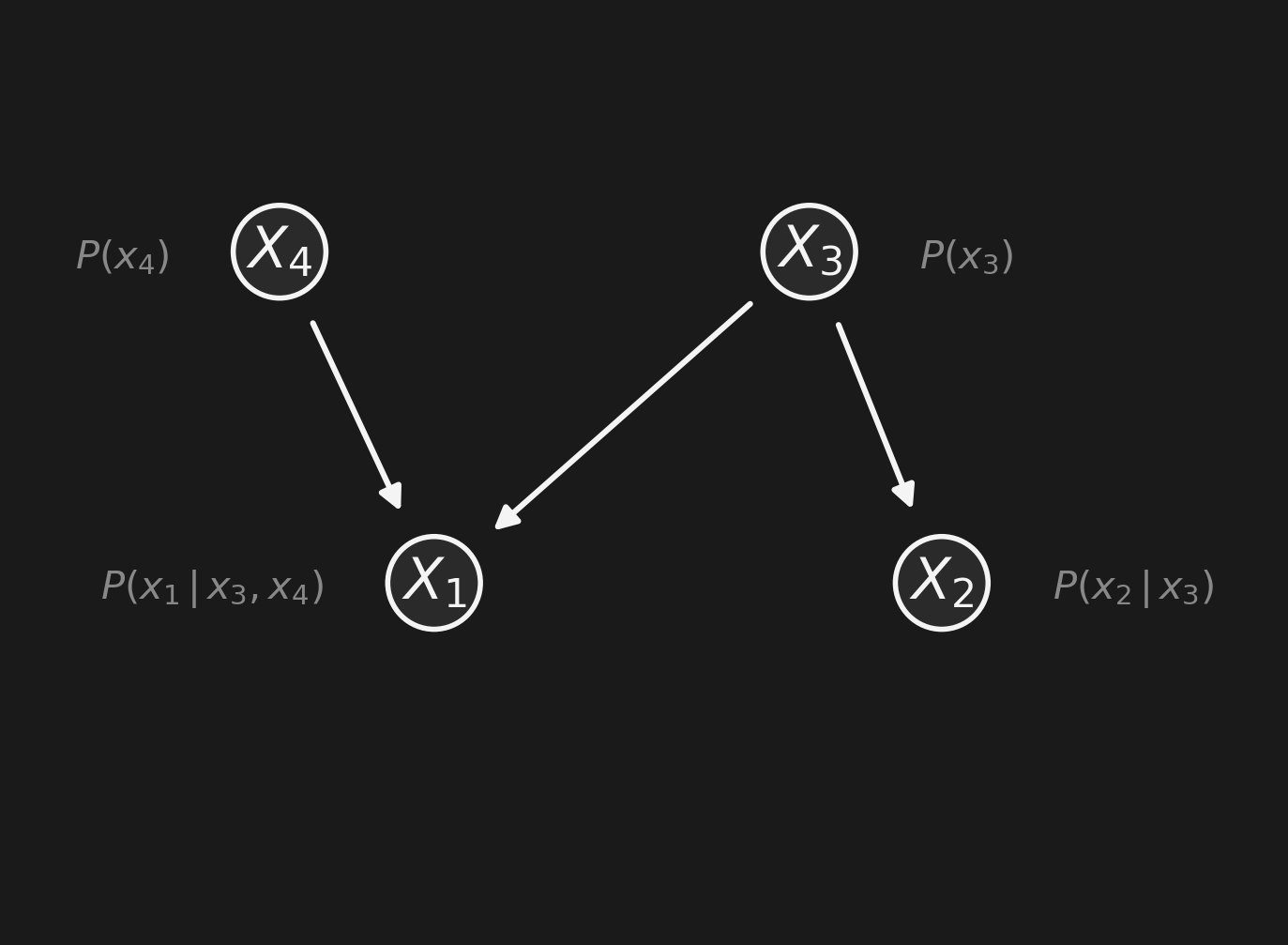
For 4 binary variables, the full joint needs \(2^4 - 1 = 15\) numbers. This Bayes net needs how many?
2値変数4つの場合、完全な同時分布 には \(2^4 - 1 = 15\) 個の数が必要。 このベイズネットは何個で済むか?
How compact is this? — answerどれくらいコンパクトか? — 答え
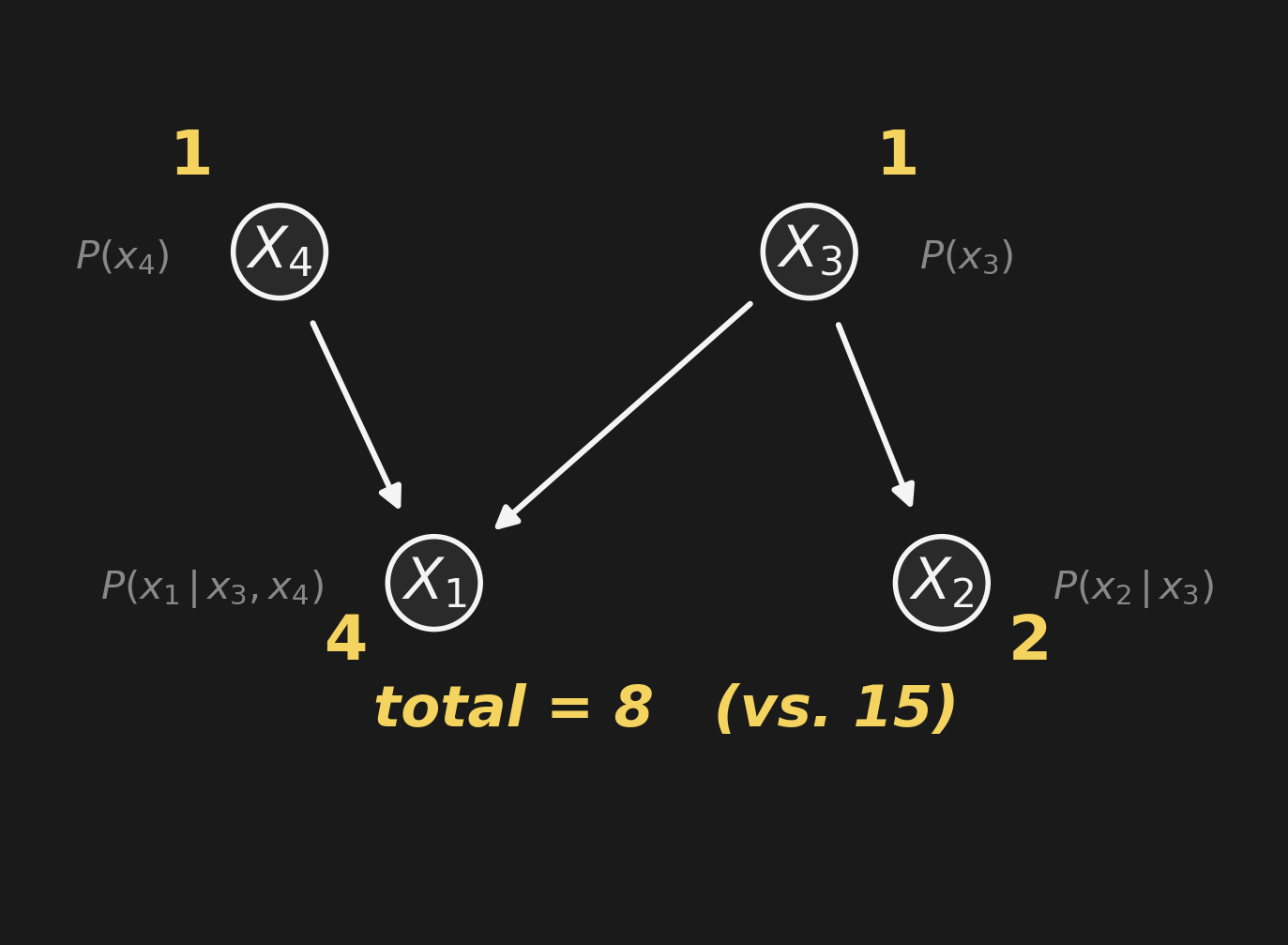
8 vs. 15. Modest gain here — exponential gain at scale.
8 個 vs. 15 個。ここでは控えめな差 — 規模が大きくなると指数的な差に。
Same network, different costume同じネット、違う衣装
Chibany versionチバニー版
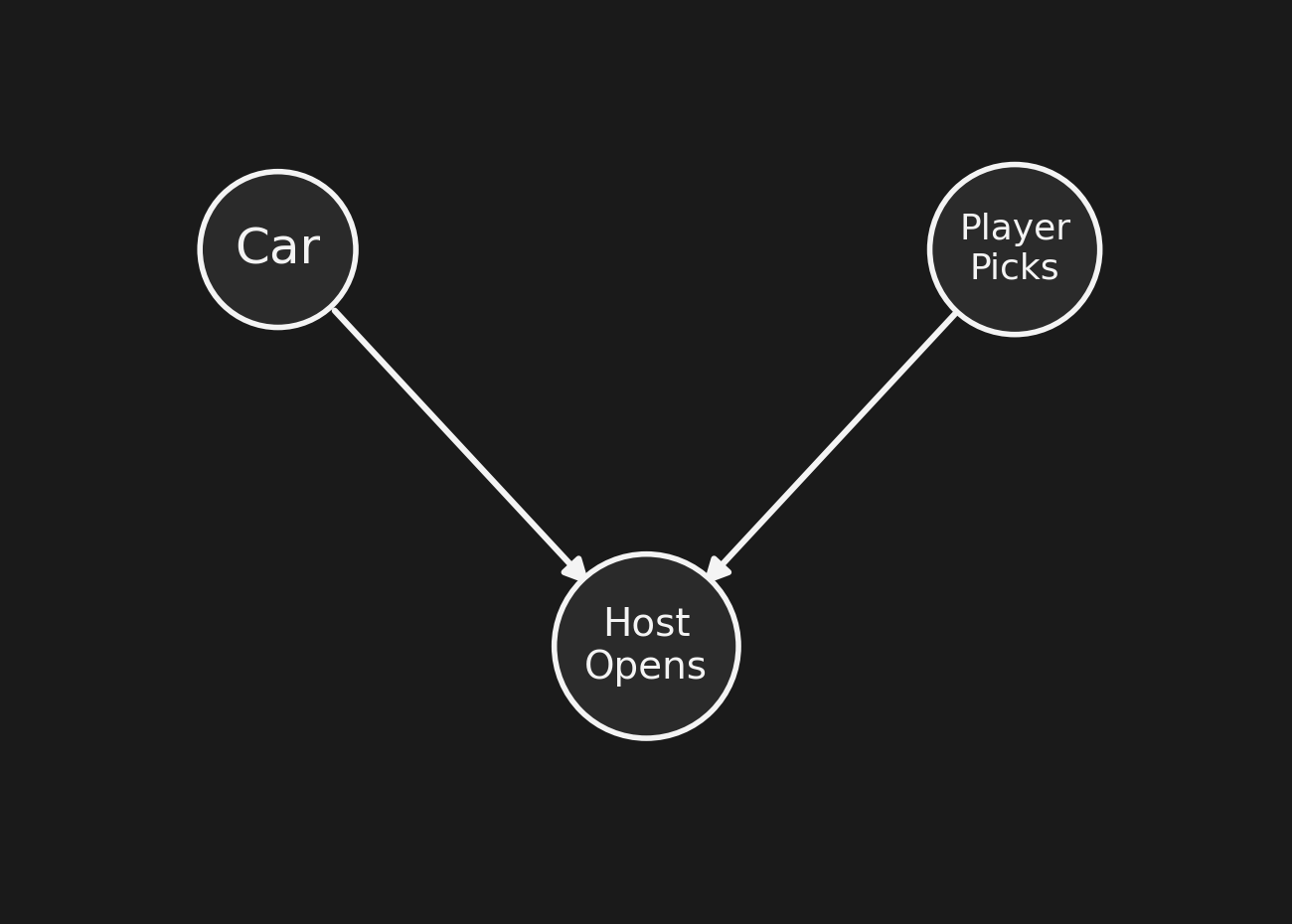
Classic Monty Hall古典的なモンティ・ホール
Car / Host / Player and Tonkatsu / Cafeteria / Chibany — literally the same network. The 2/3 vs 1/3 answer is structural.
車 / ホスト / プレイヤー と トンカツ / 店員 / チバニー — 文字通り 同じネットワーク。 2/3 vs 1/3 の答えはネットワーク構造から来る。
Chain: A → B → Cチェーン: A → B → C
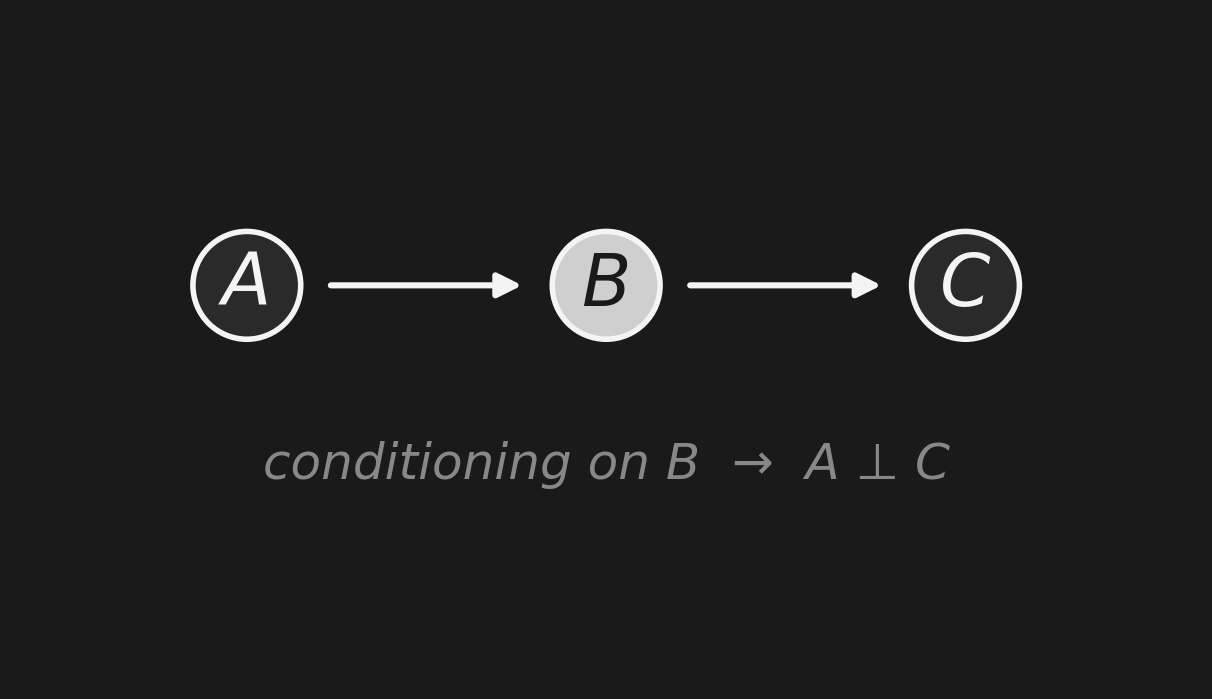
Conditioning on the middle node blocks information flow.
\[A \;\perp\; C \;\mid\; B\]
中間ノードに条件付けると、情報の流れは 遮断 される。
\[A \;\perp\; C \;\mid\; B\]
Fork: A ← B → Cフォーク: A ← B → C
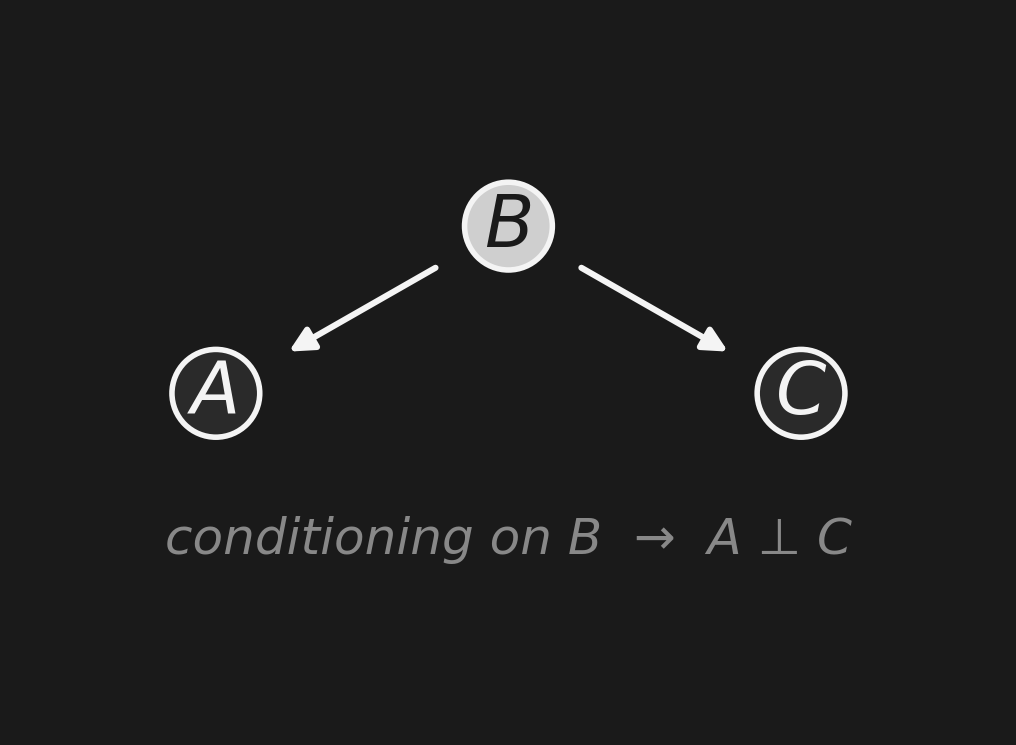
A common cause. Conditioning on the cause blocks information flow.
\[A \;\perp\; C \;\mid\; B\]
共通原因。原因に条件付けると、情報の流れは 遮断 される。
\[A \;\perp\; C \;\mid\; B\]
Collider: A → B ← Cコライダー: A → B ← C
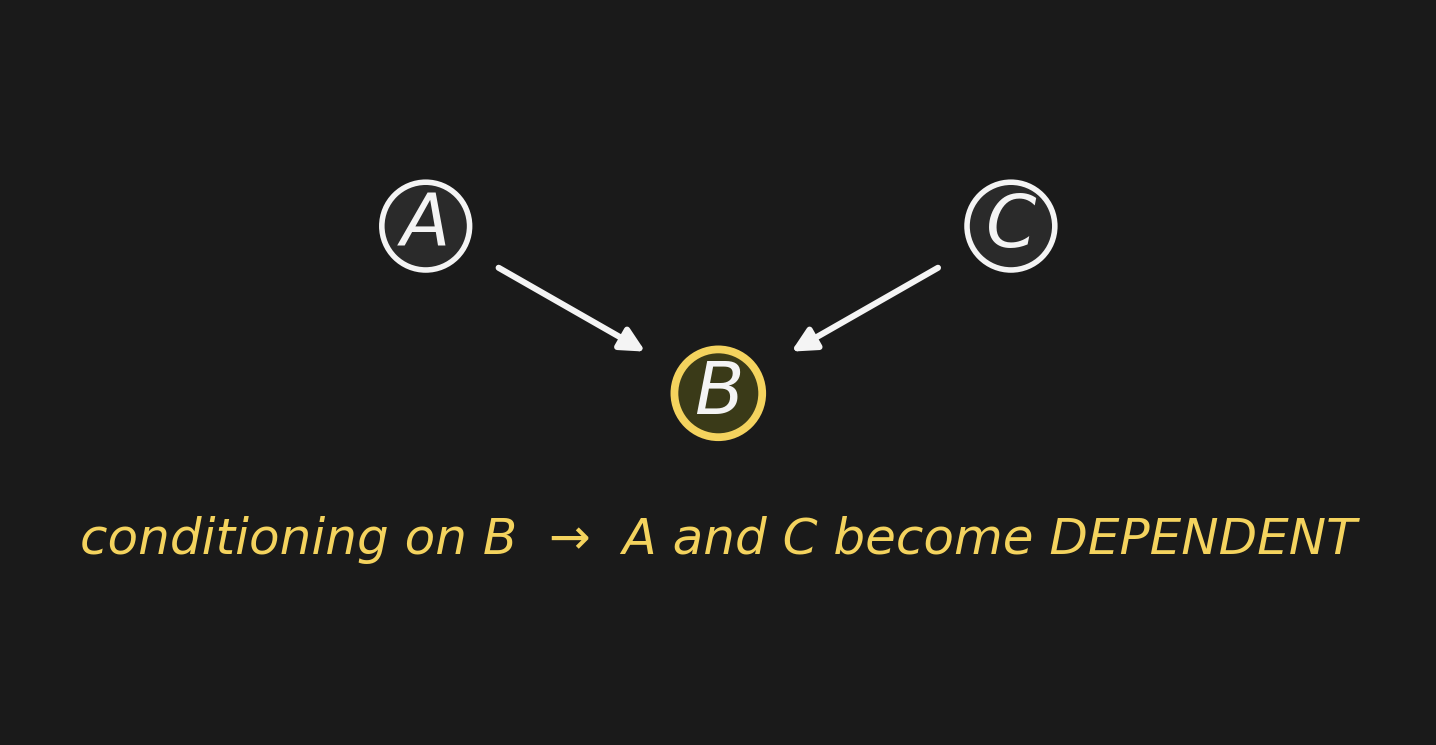
A common effect. Conditioning on the effect induces dependence between the otherwise-independent causes.
\[A \;\perp\; C \quad\text{but}\quad A \;\not\perp\; C \;\mid\; B\]
This is backwards from chain and fork. It’s the surprise of the lecture.
共通の結果。結果に条件付けると、もともと独立だった原因間に依存性が 生じる。
\[A \;\perp\; C \quad\text{しかし}\quad A \;\not\perp\; C \;\mid\; B\]
これはチェーンやフォークと 逆向き。今日の講義の意外なポイント。
Markov blanketマルコフブランケット
Definition. The Markov blanket of node \(X\):
- parents of \(X\)
- children of \(X\)
- other parents of \(X\)’s children (the “spouses”)
Conditioning on the Markov blanket makes \(X\) independent of everything else in the network.
The spouses are the non-obvious part — they’re there because of collider conditioning flowing through \(X\)’s children.
定義. ノード \(X\) のマルコフブランケット:
- \(X\) の 親
- \(X\) の 子
- \(X\) の子の 他の親(「配偶者」)
マルコフブランケットに条件付けると、\(X\) はネットワーク中の 他のすべてから独立 になる。
配偶者は自明でないところ — \(X\) の子を通って流れる コライダーへの条件付け のために含まれる。
![]()
Sprinkler / Rain / Wet grassスプリンクラー / 雨 / 濡れた芝生
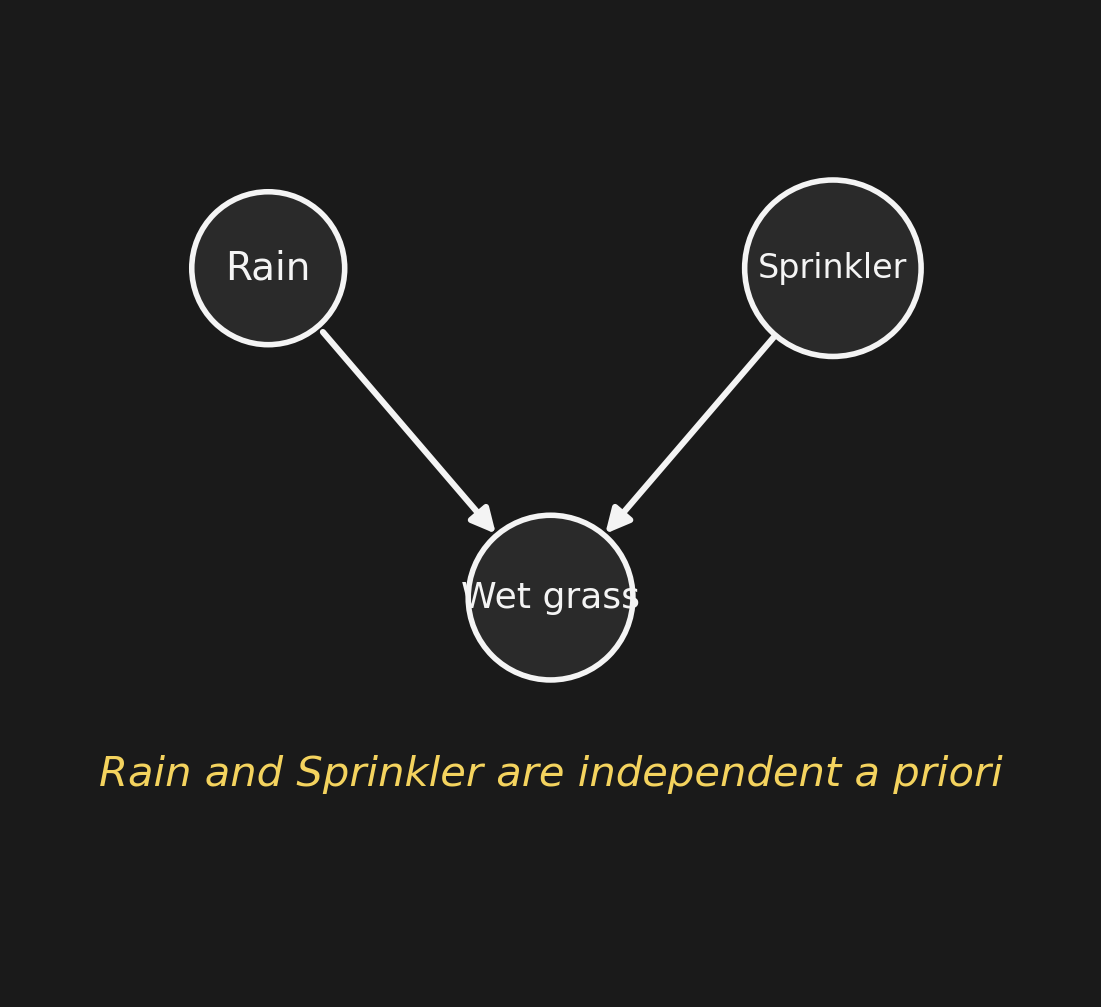
Three nodes: Rain (\(R\)), Sprinkler (\(S\)), Wet grass (\(W\)). Two independent causes of wet grass. A priori, \[P(R) = 0.3, \quad P(S) = 0.3, \quad P(R, S) = P(R)\,P(S).\] Rain and Sprinkler are independent. The grass is wet if either cause fires: \[W = 1 \iff (R = 1)\ \text{or}\ (S = 1). \quad\text{(deterministic OR)}\]
\(R\), \(S\), \(W\) from here on.
3つのノード:雨 (\(R\))、スプリンクラー (\(S\))、濡れた芝生 (\(W\))。濡れた芝生の独立な2つの原因。事前分布は、 \[P(R) = 0.3, \quad P(S) = 0.3, \quad P(R, S) = P(R)\,P(S).\] 雨とスプリンクラーは 独立。どちらか の原因が起これば芝生は濡れる: \[W = 1 \iff (R = 1)\ \text{または}\ (S = 1). \quad\text{(決定的 OR)}\]
以降、\(R\), \(S\), \(W\) と略記。
Observe wet grass濡れた芝生を観測
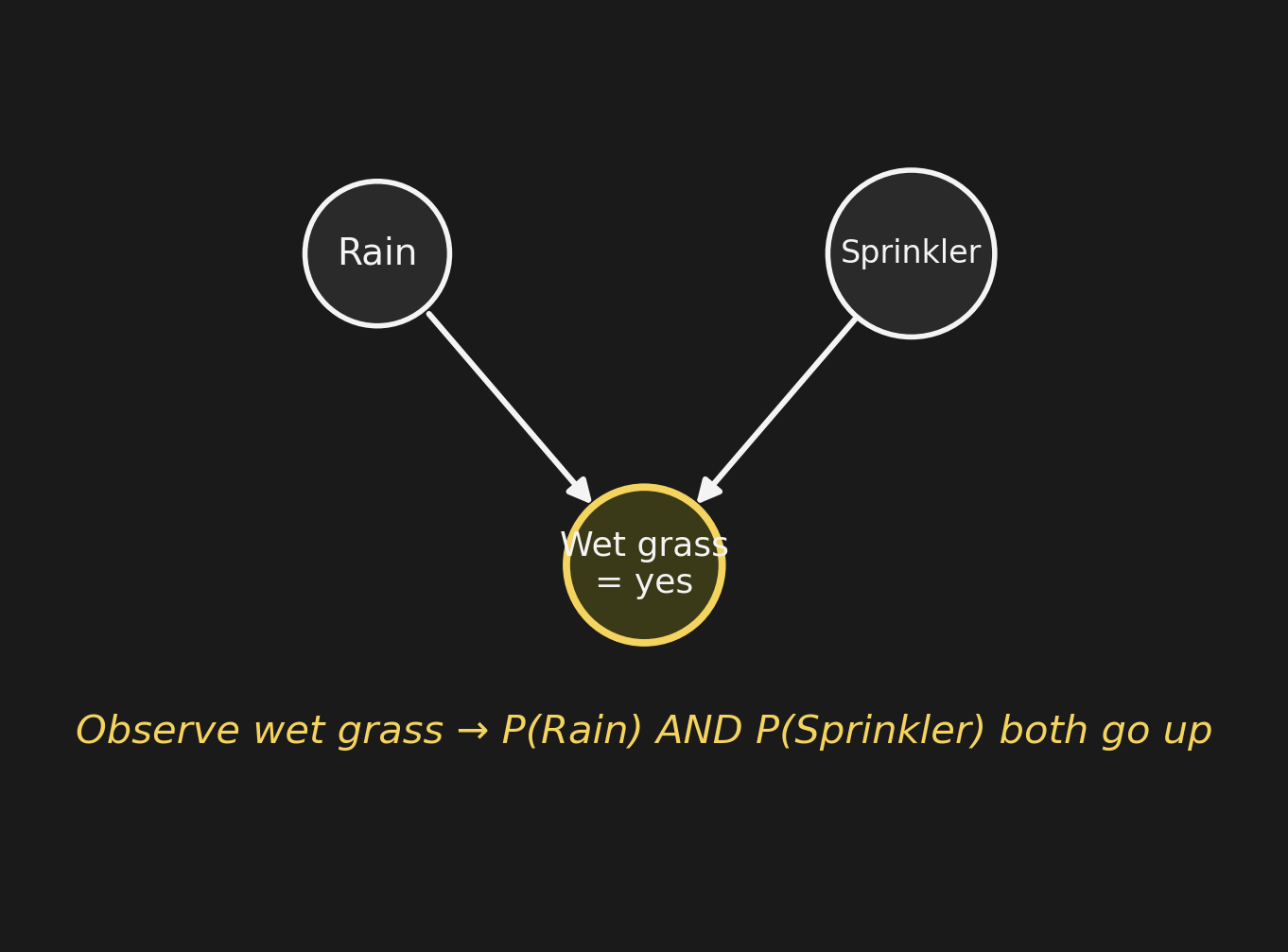
Now we walk outside: the grass is wet (\(W = 1\)). Both probabilities rise: \[P(R \mid W) \approx 0.59, \quad P(S \mid W) \approx 0.59.\] Either cause is now more plausible — the observation supports both.
さて、外に出ると:芝生が濡れている (\(W = 1\))。両方の確率が 上がる: \[P(R \mid W) \approx 0.59, \quad P(S \mid W) \approx 0.59.\] どちらの原因も今や確からしくなる — 観測は両方を支持する。
Also learn sprinkler was onさらに、スプリンクラーが作動していたと知る
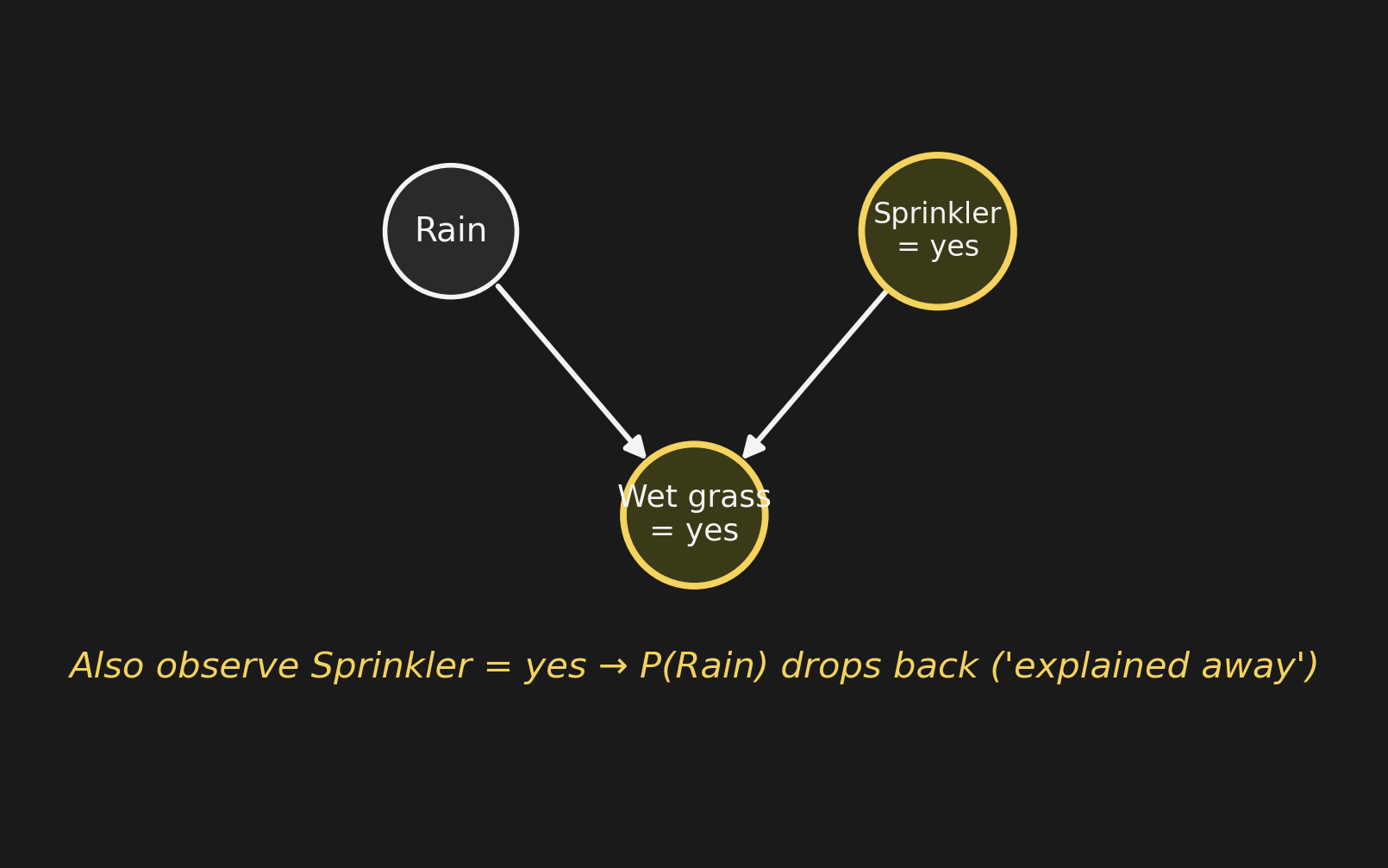
A neighbor mentions: “I saw your sprinkler running this morning.” So \(S = 1\). Now: \[P(R \mid W, S = 1) = 0.3 = P(R).\] Rain’s probability drops all the way back to its prior — sprinkler already “explains” the wetness, so wet grass tells us nothing more about rain.
Conditioning on the collider’s parents and the collider itself induces this competition. That’s explaining away.
近所の人が言う:「今朝あなたのスプリンクラーが動いているのを見たよ。」つまり \(S = 1\)。今度は: \[P(R \mid W, S = 1) = 0.3 = P(R).\] 雨の確率が 事前分布まで完全に戻る — スプリンクラーが濡れていることを既に「説明」したので、 濡れた芝生は雨について もう何も教えてくれない。
コライダーの親 と コライダー自身に条件付けることで、この競合が生まれる。 これが説明はがし。
The confound共通原因(交絡)
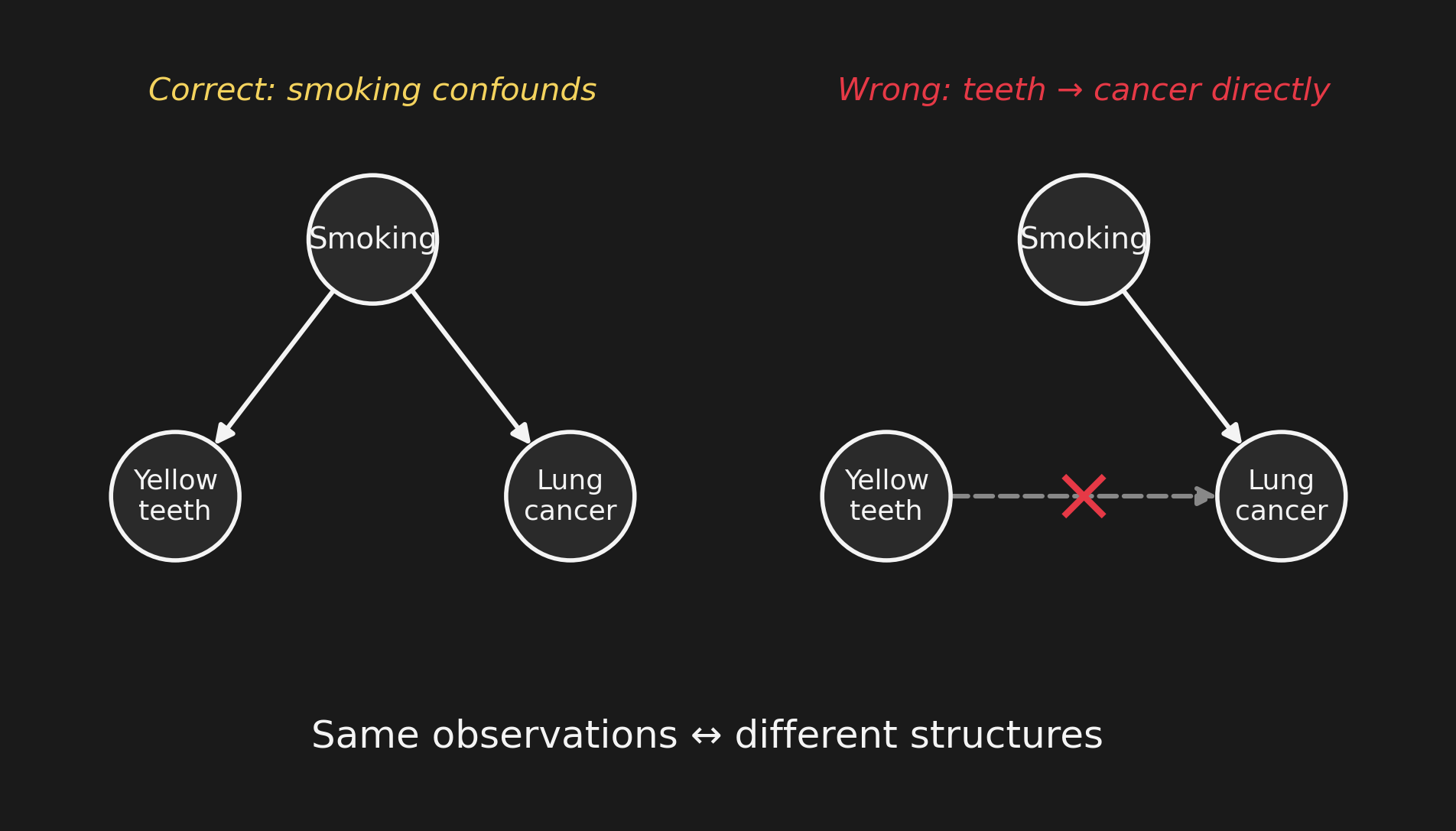
Three variables: Smoking (\(S\)), Yellow teeth (\(T\)), Lung cancer (\(L\)). Two structures give exactly the same statistical correlation:
- \(S\) causes both \(T\) and \(L\) (correct).
- \(T\) directly causes \(L\) (wrong, but observationally indistinguishable).
Observation alone cannot tell them apart. You’d see the same correlation either way.
\(S\), \(T\), \(L\) from here on.
3つの変数:喫煙 (\(S\))、黄色い歯 (\(T\))、肺がん (\(L\))。2つの構造が まったく同じ 統計的相関を生む:
- \(S\) が \(T\) と \(L\) の両方の原因(正しい)。
- \(T\) が直接 \(L\) を引き起こす(誤りだが、観測上は区別できない)。
観測だけではこの2つを区別できません。 どちらの構造でも同じ相関が見られる。
以降、\(S\), \(T\), \(L\) と略記。
Three causal stories, one correlation: chain1つの相関、3つの因果ストーリー:チェーン
Story 1 (chain): \(T \to S \to L\) — yellow teeth cause smoking, smoking causes lung cancer. Implausible, but observationally consistent.
Conditional independence: \(T \perp L \mid S\).
ストーリー1(チェーン): \(T \to S \to L\) — 黄色い歯が喫煙の原因で、 喫煙が肺がんの原因。実際にはありそうにないが、観測上は整合的。
条件付き独立性: \(T \perp L \mid S\)。
Three causal stories, one correlation: fork1つの相関、3つの因果ストーリー:フォーク
Story 2 (fork): \(T \leftarrow S \to L\) — smoking causes both. The real story for the smoking-yellow-teeth-cancer triangle.
Conditional independence: \(T \perp L \mid S\).
Identical to chain! Observation cannot tell these apart.
ストーリー2(フォーク): \(T \leftarrow S \to L\) — 喫煙が両方の原因。 喫煙-黄色い歯-肺がんの三角関係の 本当の ストーリー。
条件付き独立性: \(T \perp L \mid S\)。
チェーンと同一! 観測ではこの2つを区別できません。
Three causal stories, one correlation: collider1つの相関、3つの因果ストーリー:コライダー
Story 3 (collider): \(T \to S \leftarrow L\) — yellow teeth and lung cancer each independently cause smoking (also implausible, but bear with it).
Conditional dependence: \(T \not\perp L \mid S\).
Observationally distinct — but the wrong structure for a smoking confound. Most real-world confounds are forks, indistinguishable from chains.
ストーリー3(コライダー): \(T \to S \leftarrow L\) — 黄色い歯と肺がんが それぞれ独立に喫煙の原因(これもありそうにないが、お付き合いください)。
条件付き従属性: \(T \not\perp L \mid S\)。
観測で区別できる — しかし、喫煙の交絡には合わない構造。 現実の交絡の多くはフォークで、チェーンとは区別できません。
The original network元のネットワーク
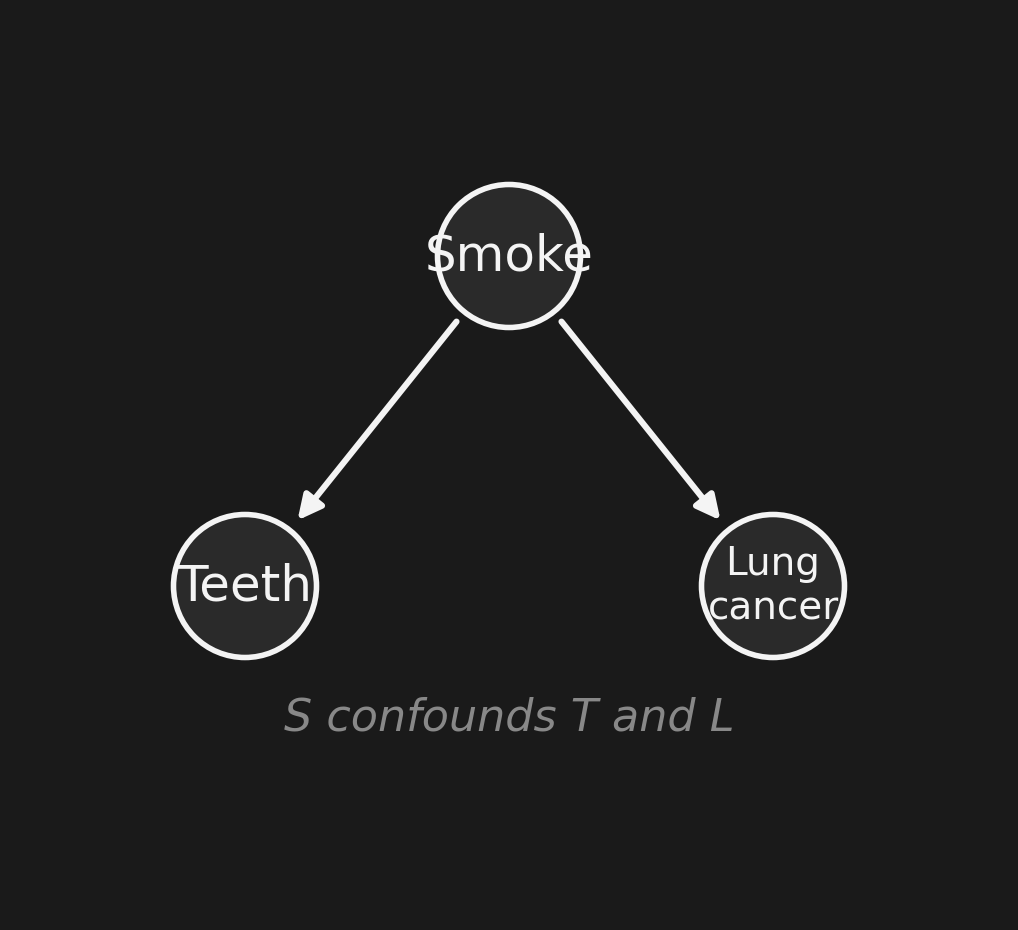
\(S \to T\) (smoking causes yellow teeth), \(S \to L\) (smoking causes lung cancer). \(T\) and \(L\) are correlated because of the common cause \(S\).
If we observe \(T = \text{yellow}\), we update our belief about \(S\), and therefore about \(L\). Hence \(P(L \mid T = \text{yellow}) > P(L)\).
\(S \to T\)(喫煙が歯を黄色くする)、\(S \to L\)(喫煙が肺がんの原因)。 \(T\) と \(L\) は共通原因 \(S\) を通じて 相関する。
\(T = \text{黄色}\) を 観測 すると、\(S\) についての信念が更新され、 そのため \(L\) についても更新される。だから \(P(L \mid T = \text{黄色}) > P(L)\)。
do(T = white): cut the incoming arrowdo(T = 白): 入ってくる矢印を切る
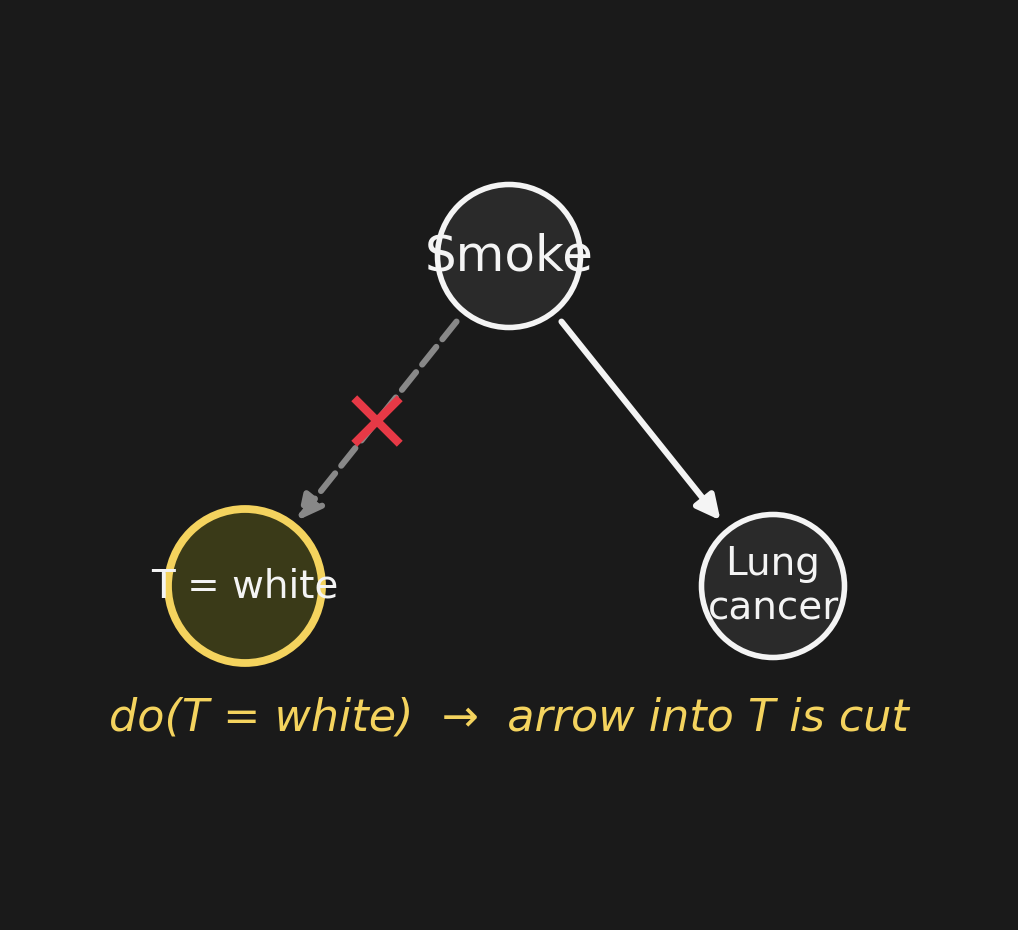
Graph surgery. We set \(T = \text{white}\) by intervention — we paid for whitening. The intervention cuts the incoming arrow \(S \to T\).
Why cut? Because \(T\) is no longer being generated by smoking. \(T\) is being generated by Chibany’s wallet. The mechanism changed.
グラフ手術. 介入によって \(T = \text{白}\) にする — 歯を白くする処置にお金を払った。 介入は 入ってくる矢印 \(S \to T\) を切断する。
なぜ切る?\(T\) はもはや喫煙によって 生成されていない から。\(T\) はチバニーの財布に よって生成されている。メカニズムが変わったのです。
Compute P(L | do(T = white))P(L | do(T = 白)) を計算
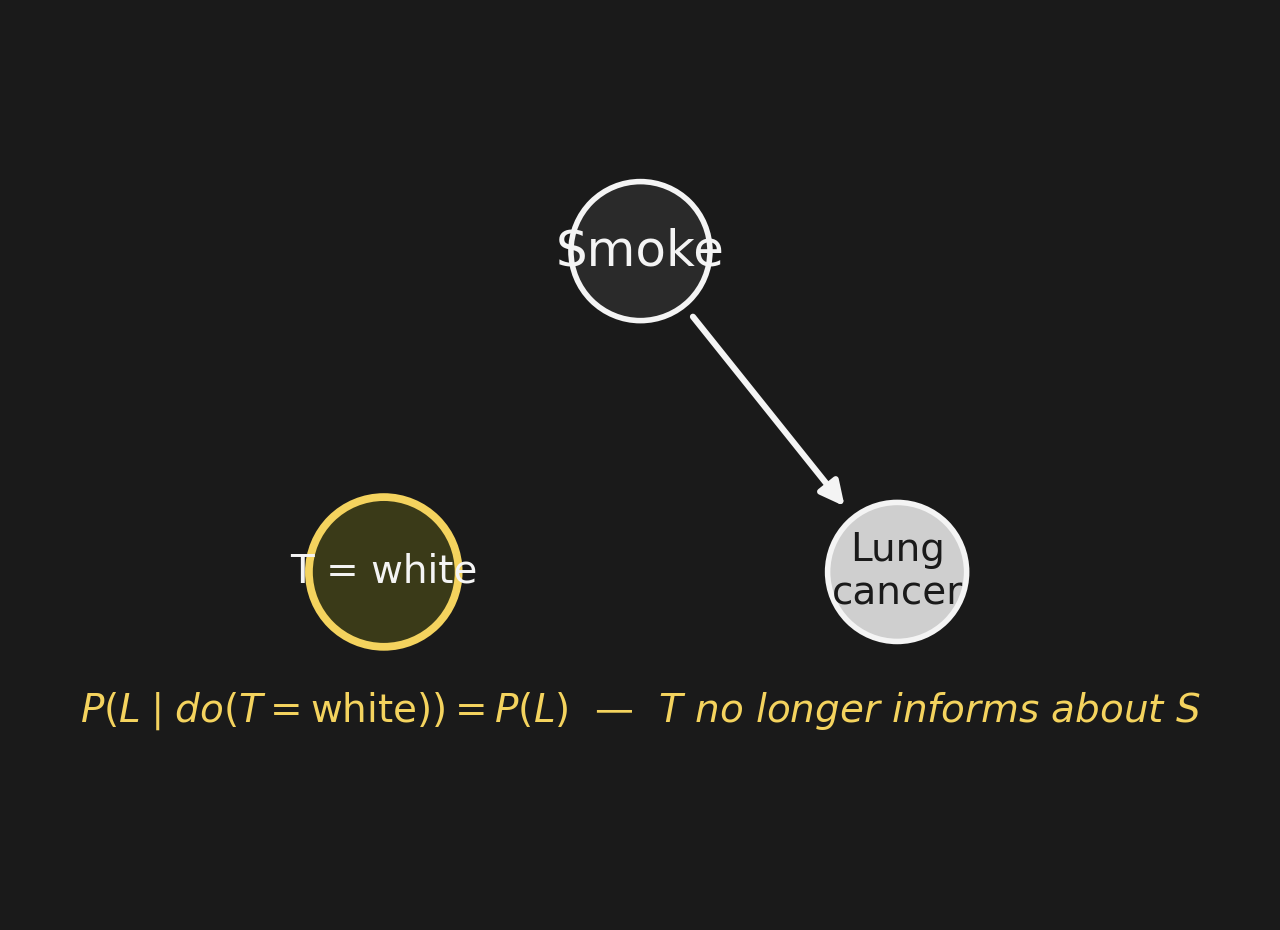
After surgery, \(T\) has no parents. The factorization becomes: \[P(S, L, T = \text{white}) = P(S) \, P(L \mid S).\]
Marginalize over \(S\) to get \(P(L \mid do(T = \text{white}))\): \[P(L \mid do(T = \text{white})) = \sum_S P(L \mid S) \, P(S) = P(L).\]
Intervention severed the path from \(T\) back to \(L\) through \(S\). \(T\) no longer carries any information about \(S\), so knowing \(T\) tells you nothing new about \(L\).
手術後、\(T\) には親がない。因数分解は次のようになる: \[P(S, L, T = \text{白}) = P(S) \, P(L \mid S).\]
\(S\) について周辺化して \(P(L \mid do(T = \text{白}))\) を得る: \[P(L \mid do(T = \text{白})) = \sum_S P(L \mid S) \, P(S) = P(L).\]
介入は \(T\) から \(S\) を経由して \(L\) へ戻る経路を断ち切った。 \(T\) はもう \(S\) について何の情報も運ばないので、\(T\) を知っても \(L\) について新しいことは何も分からない。
\(P(L \mid T)\) vs. \(P(L \mid do(T))\)\(P(L \mid T)\) vs. \(P(L \mid do(T))\)
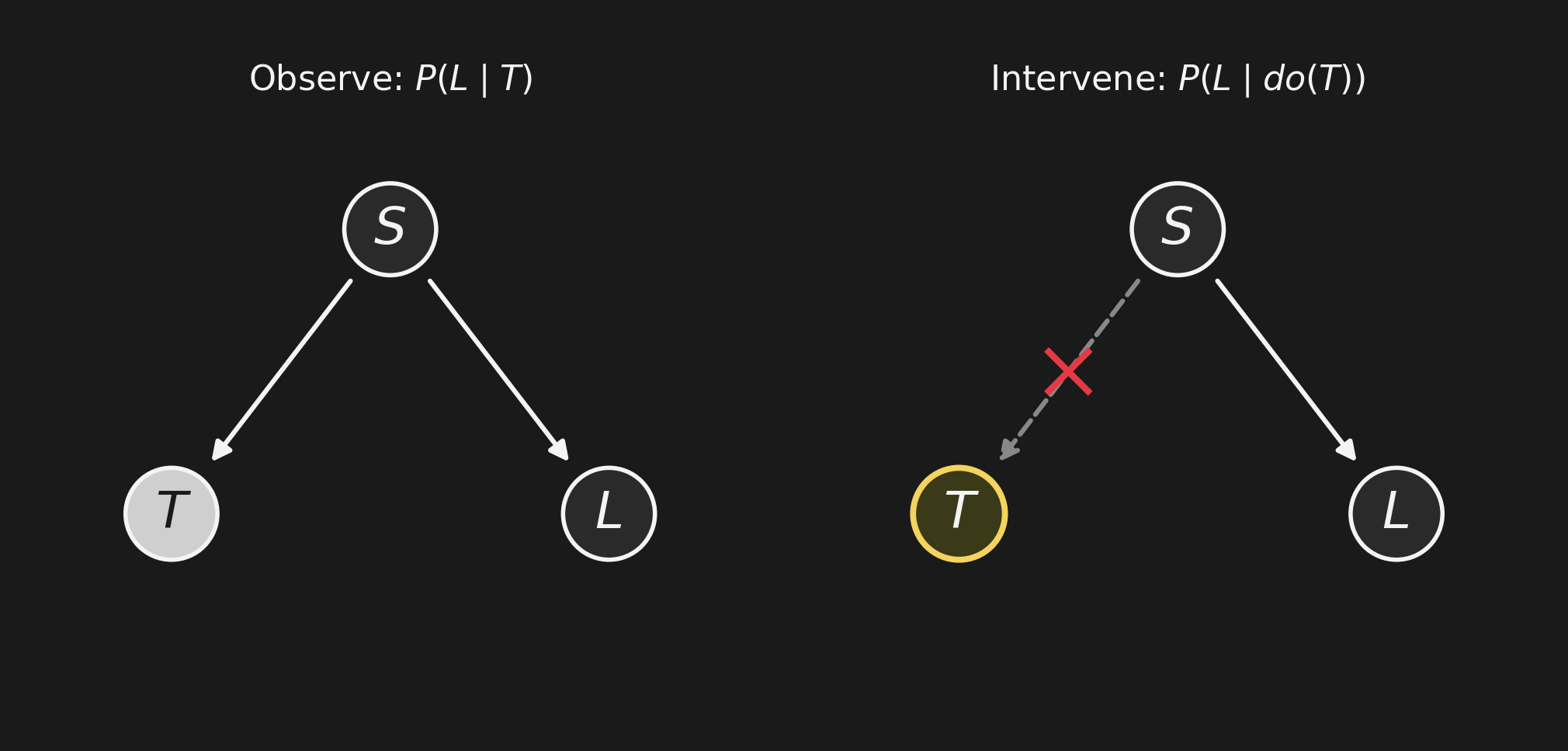
Same notation, different operation, different answer.
- \(P(L \mid T)\): passive observation. Yellow teeth tell you about smoking.
- \(P(L \mid do(T))\): active intervention. Yellow teeth tell you about the dentist’s bill.
同じ記号、違う操作、違う答え。
- \(P(L \mid T)\): 受動的な観測。黄色い歯は喫煙について教えてくれる。
- \(P(L \mid do(T))\): 能動的な介入。黄色い歯は歯科医の請求書について教えてくれる。
The blicket detectorブリケット検出器
A children’s experiment (Gopnik & Sobel, 2000). A “blicket” is whatever makes the machine light up. Children watch blocks placed on the detector and infer which blocks are blickets.
子ども向けの実験(ゴプニックとソベル、2000)。「ブリケット」とは、機械を光らせる ものすべて。子どもは積み木が検出器に置かれるのを見て、どの積み木がブリケットかを推論する。
Backwards blockingバックワード・ブロッキング
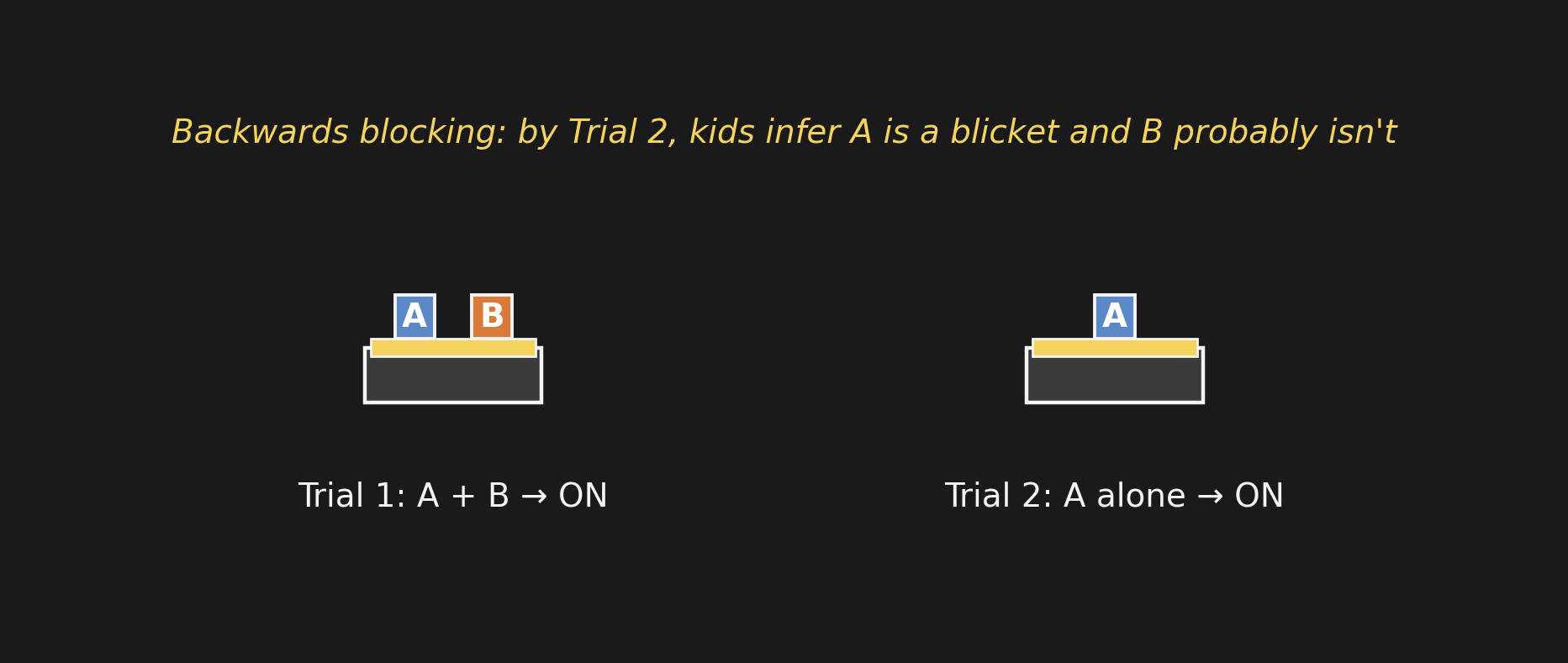
- Trial 1: A and B together → detector ON.
- Trial 2: A alone → detector ON.
After Trial 2, what do kids think about B?
- 試行1: AとBを一緒に → 検出器 ON。
- 試行2: Aだけ → 検出器 ON。
試行2の後、子どもはBについてどう思う?
Children match the Bayes net子どもはベイズネットと一致する
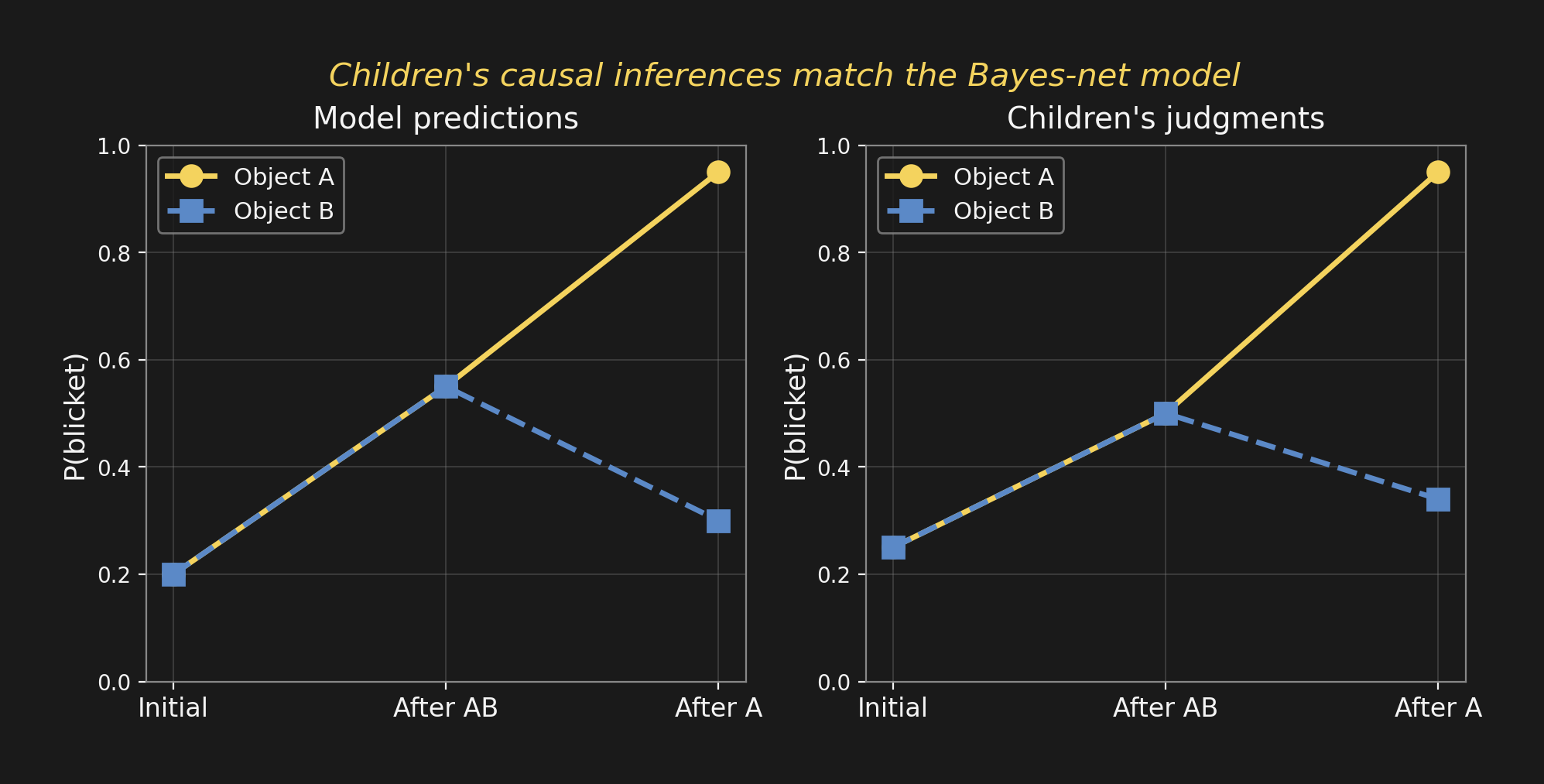
Children’s judgments drop for object B after the A-alone trial — even though nothing changed about B’s data. Children do graph surgery. They reason about the causal structure, not just statistical patterns.
The formal machinery isn’t just for engineers.
子どもの判断は、Aだけの試行のあとBについて 下がる — Bのデータについては 何も変わっていないのに。子どもはグラフ手術をしている。 統計パターンだけでなく、 因果構造について推論しているのです。
この形式的な仕組みは、エンジニアだけのものではありません。
Did the prior come back?事前は戻ってくるか?
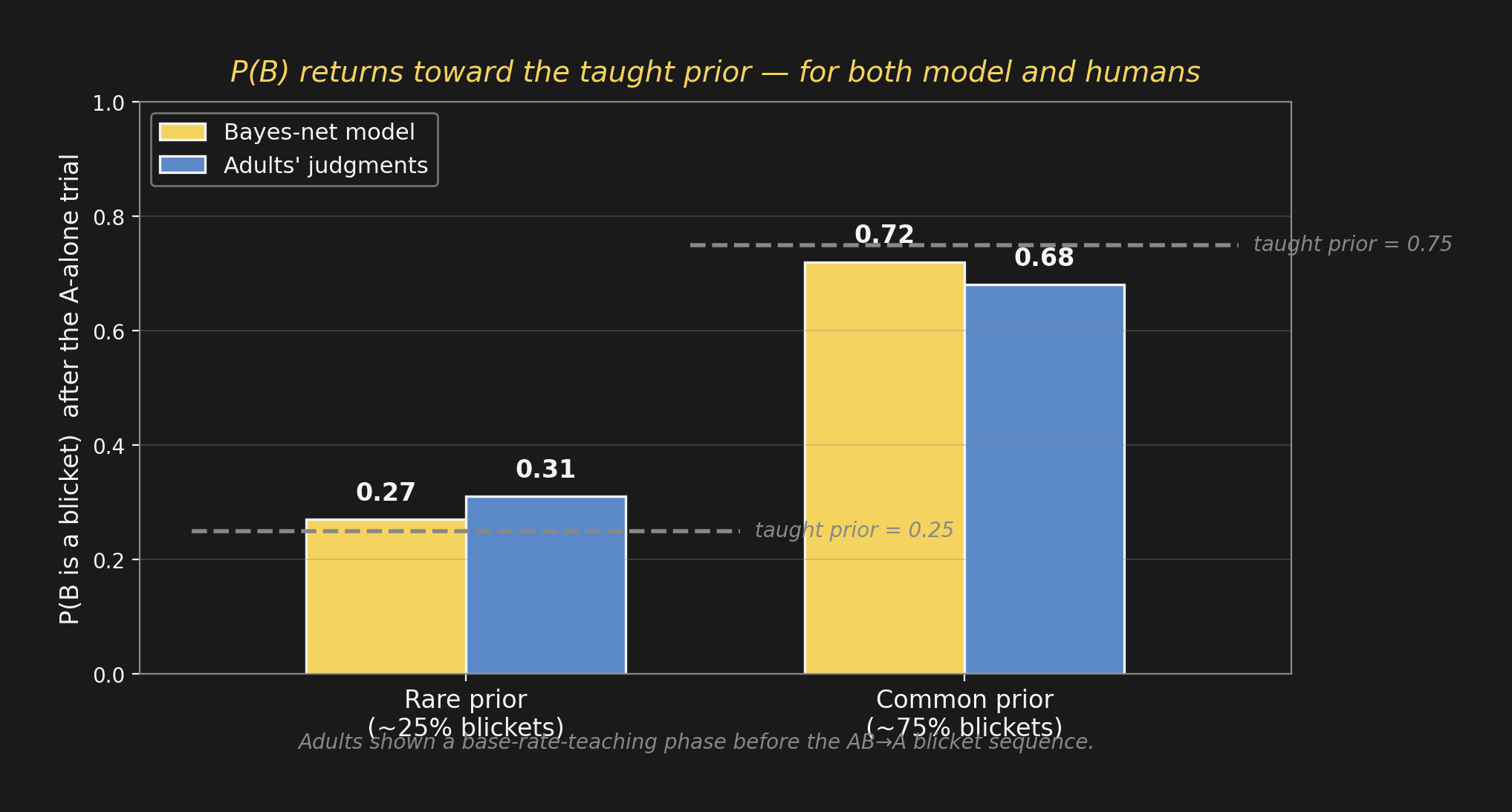
Design. Before the AB→A blicket sequence, adults watch a base-rate-teaching phase showing ~25% (“rare prior”) or ~75% (“common prior”) of arbitrary blocks are blickets. Then they run the classic backwards-blocking trials and rate \(P(B)\).
Bayes-net prediction. After A alone explains the AB result, the posterior on \(B\) should relax back toward the taught prior. Associative learning predicts a uniformly low rating regardless.
Result. Both the model AND adults snap \(P(B)\) back to the taught base rate — strong evidence that adults are reasoning Bayesianly over a causal graph, not just learning associations.
設計: AB→A の試行の前に、大人は「任意のブロックがブリケットである率」が ~25%(rare 事前)か ~75%(common 事前)かを学習する映像を見る。その後、定番の後方ブロッキング試行を行い \(P(B)\) を評価する。
ベイズネットの予測: A だけの試行が AB の結果を「説明」した後、\(B\) の事後分布は 教えられた事前に戻る。連合学習の予測は、教えた率に関係なく一律に低い評価。
結果: モデルも大人も \(P(B)\) を教えられた基準率に戻す — 大人は連合ではなく、因果グラフ上で ベイズ的に 推論している強い証拠。